
GAN
GAN
博客内容
One neural network tries to generate realistic data (note that GANs can be used to model any data distribution, but are mainly used for images these days), and the other network tries to discriminate between real data and data generated by the generator network.
The generator network uses the discriminator as a loss function and updates its parameters to generate data that starts to look more realistic.
The discriminator network, on the other hand, updates its parameters to make itself better at picking out fake data from real data. So it too gets better at its job.
The game of cat and mouse continues, until the system reaches a so-called “equilibrium,” where the generator creates data that looks real enough that the best the discriminator can do is guess randomly.
一个神经网络尝试生成真实数据(请注意,GANs 可用于对任何数据分布进行建模,但目前主要用于图像),另一个网络尝试区分真实数据和生成器网络生成的数据。
生成器网络使用鉴别器作为损失函数并更新其参数以生成开始看起来更真实的数据。
另一方面,鉴别器网络会更新其参数,以使自己更好地从真实数据中挑选出虚假数据。因此,它的工作也变得更好。
猫捉老鼠的游戏继续进行,直到系统达到所谓的“平衡”,在这种平衡中,生成器创建的数据看起来足够真实,鉴别器所能做的最好的事情就是随机猜测。
要点
标准的GAN训练循环有三个步骤:
- 用真实的训练数据集训练鉴别器。
- 用生成的数据训练鉴别器。
- 训练生成器生成数据,并使鉴别器以为它是真实数据。

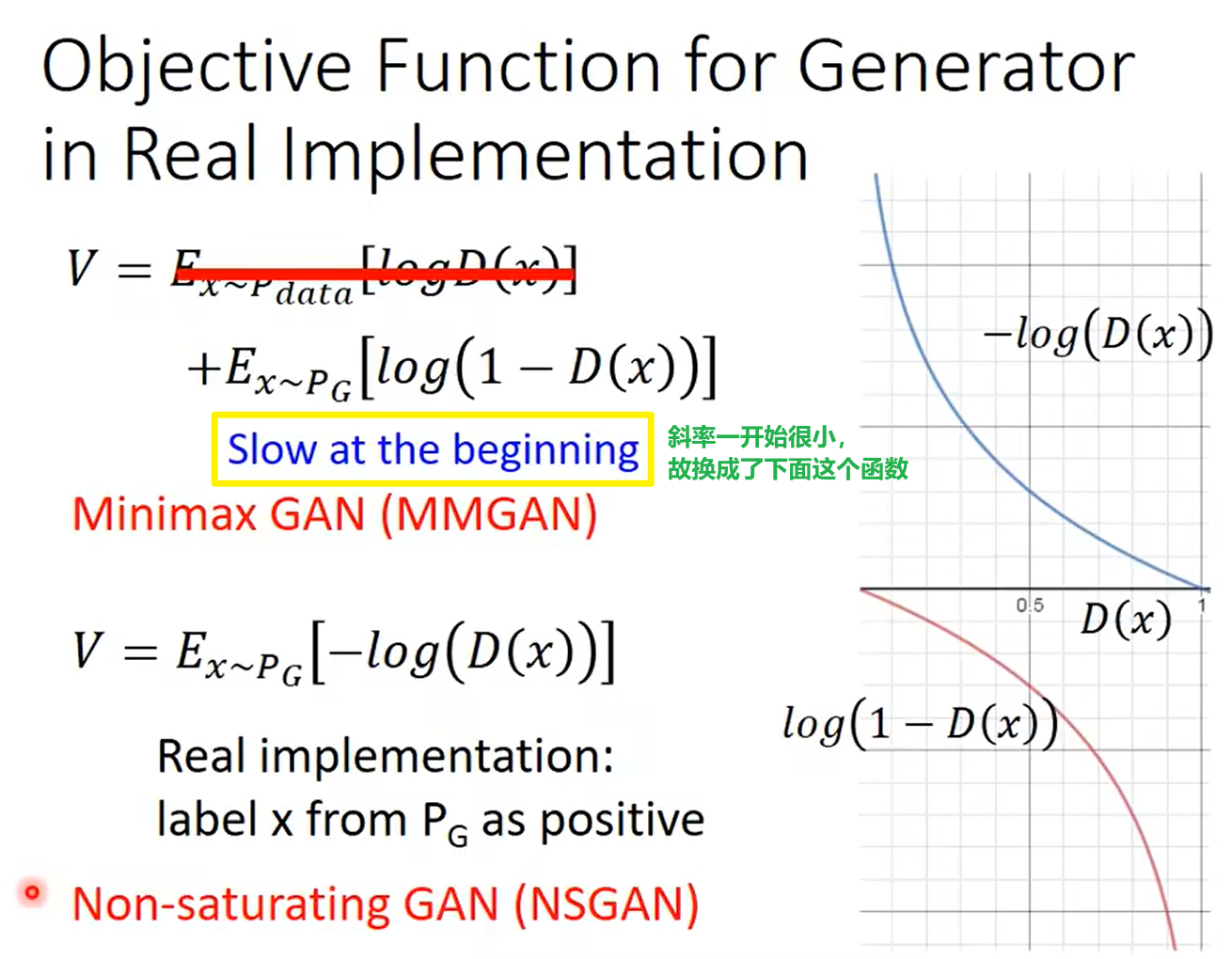
provide higher gradient in the early stage of training:
视频参考
https://www.bilibili.com/video/BV1Wv411h7kN?p=62&vd_source=909d7728ce838d2b9656fb13a31483ca
Theory behind GAN
应使$P_G$和$P_{data}$这两个分布尽可能靠近(下图公式中Div是divergence):
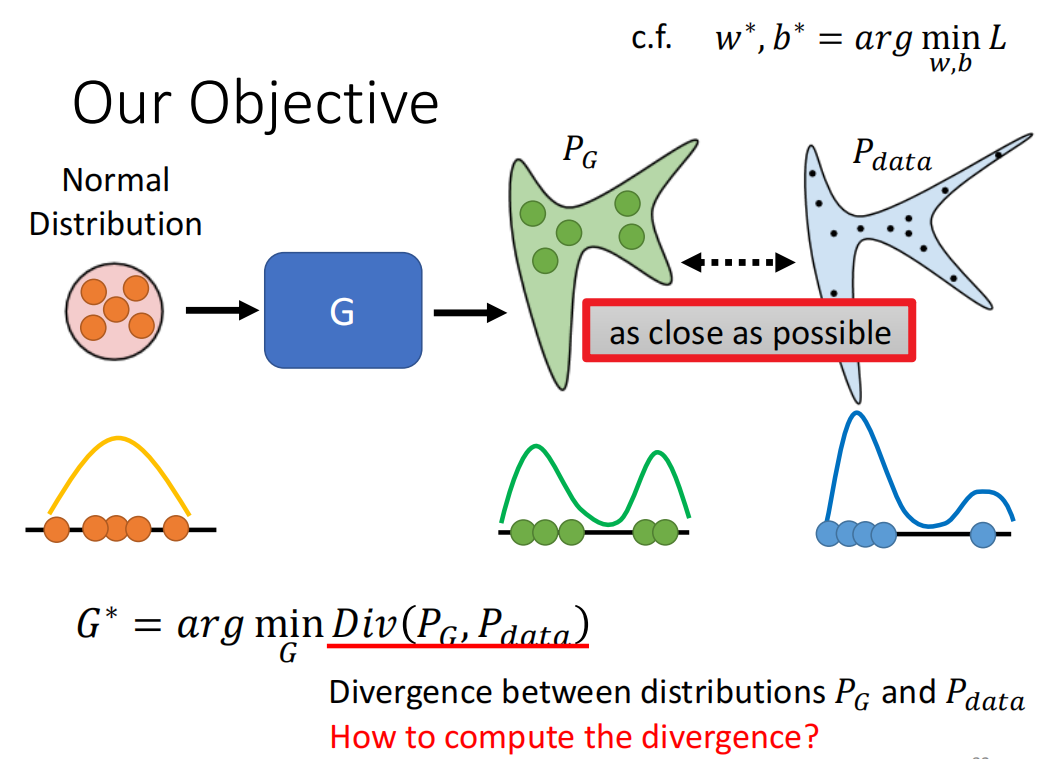
$P_G$和$P_{data}$这两个分布,我们并不知道它俩长什么样子,但是可以从这两个分布中采样:

目标函数如下:
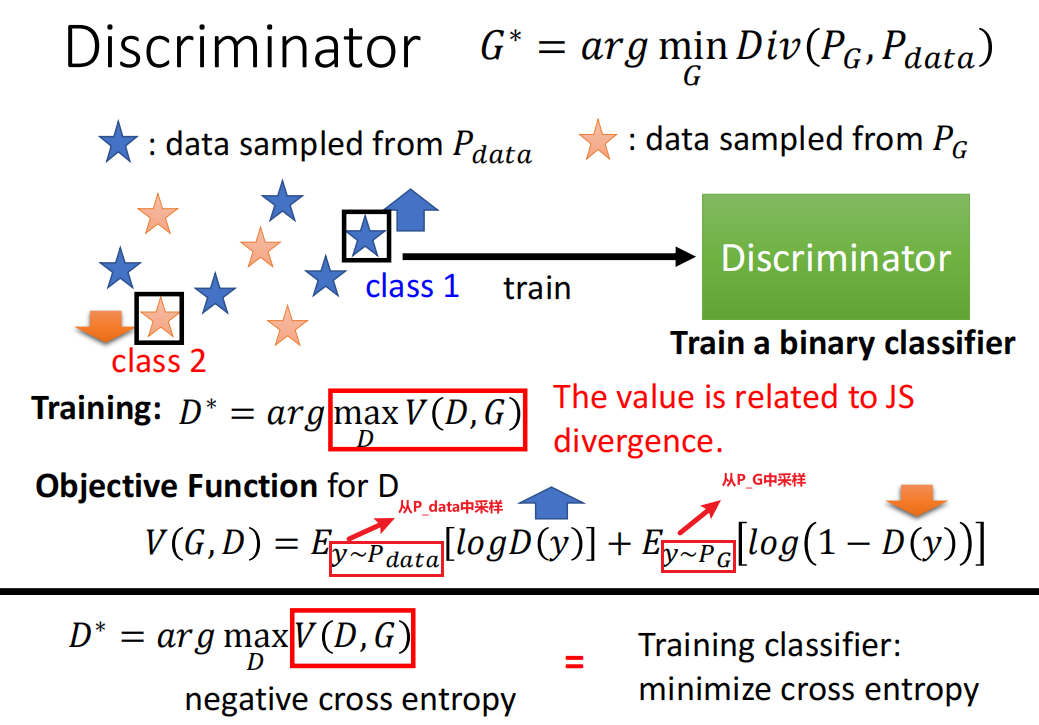
Optimizing G is equal to minimizing the JS distance:



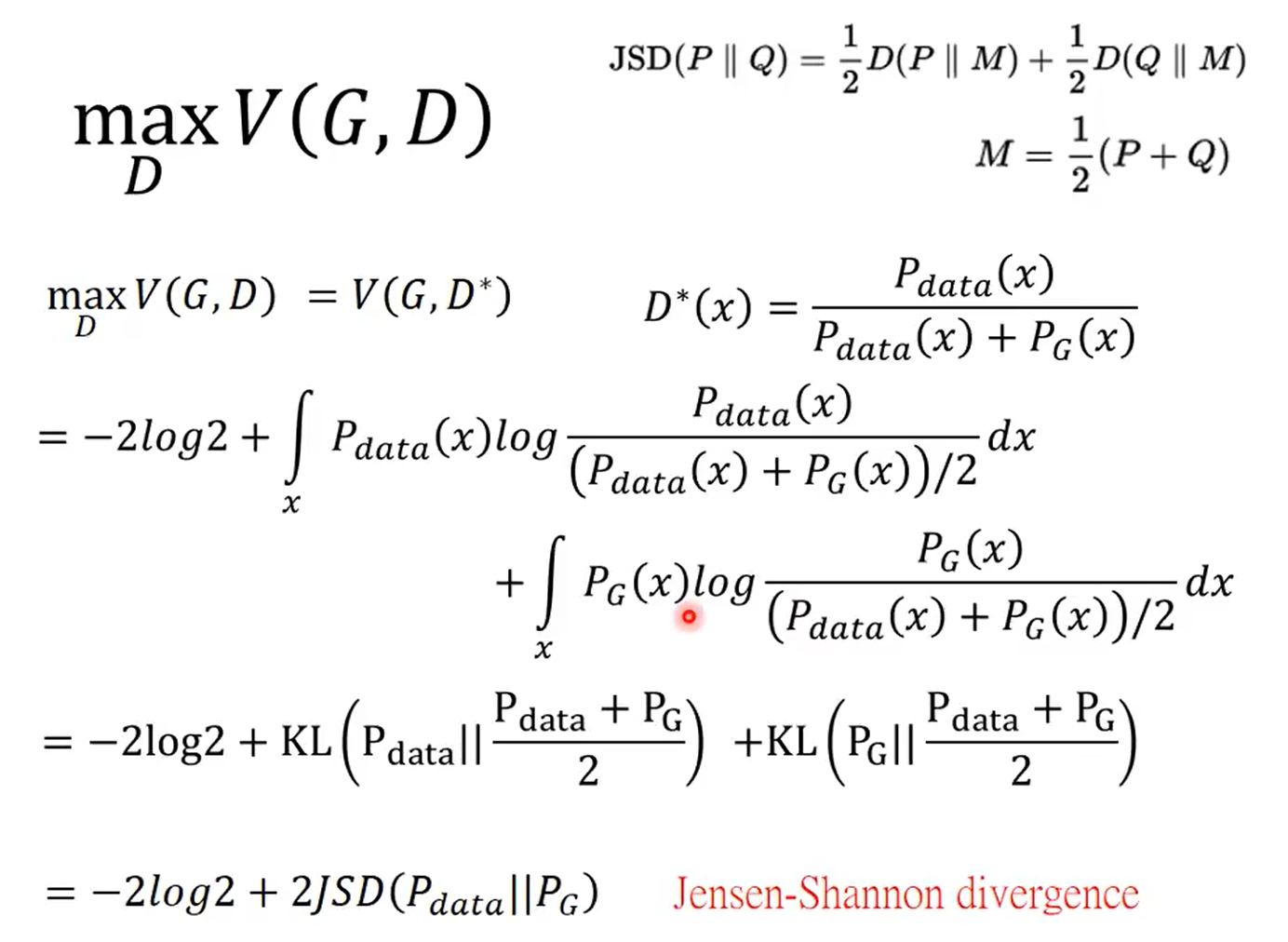
所以$Div(P_G,P_{data})$可以被替换了:
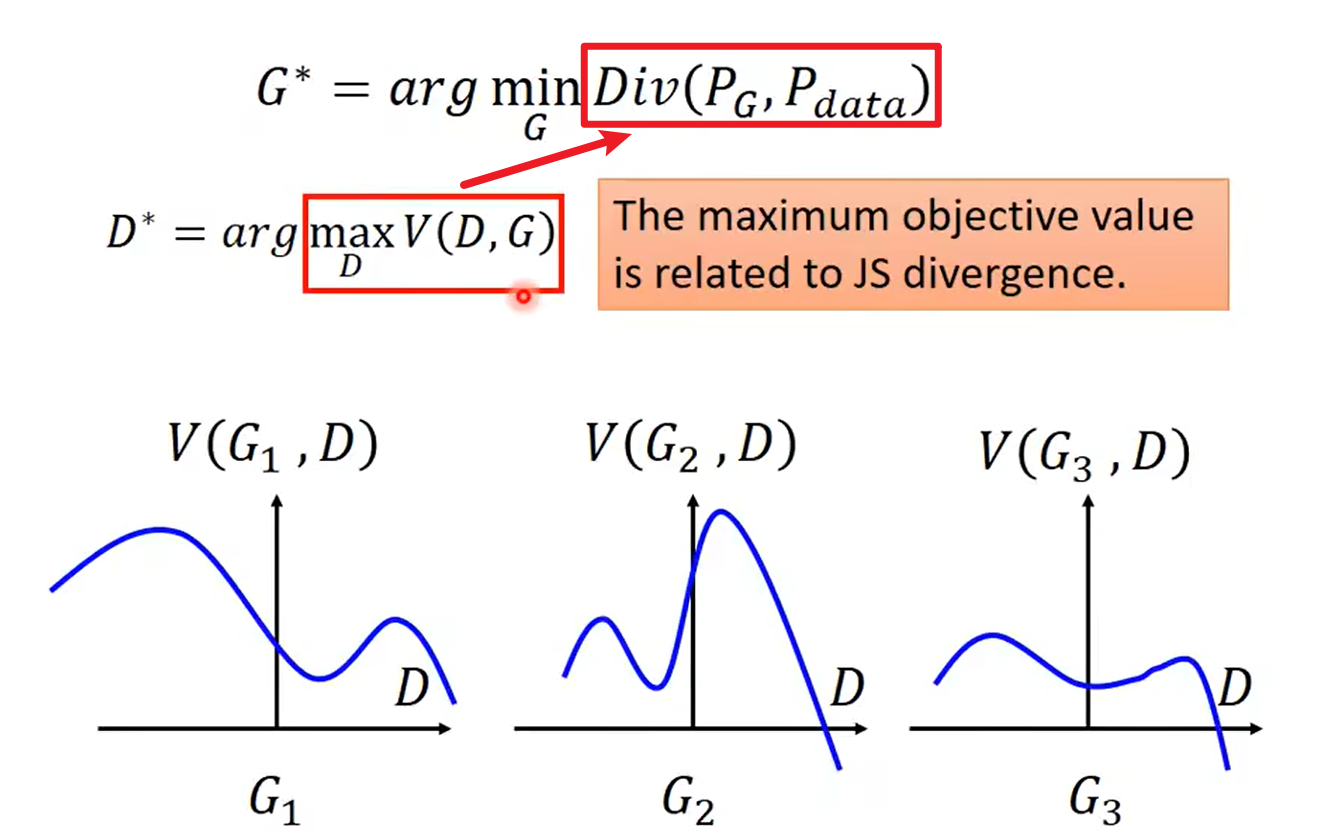
也就是:
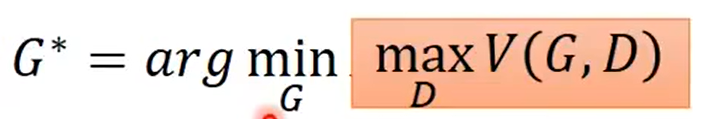
求解步骤如下:

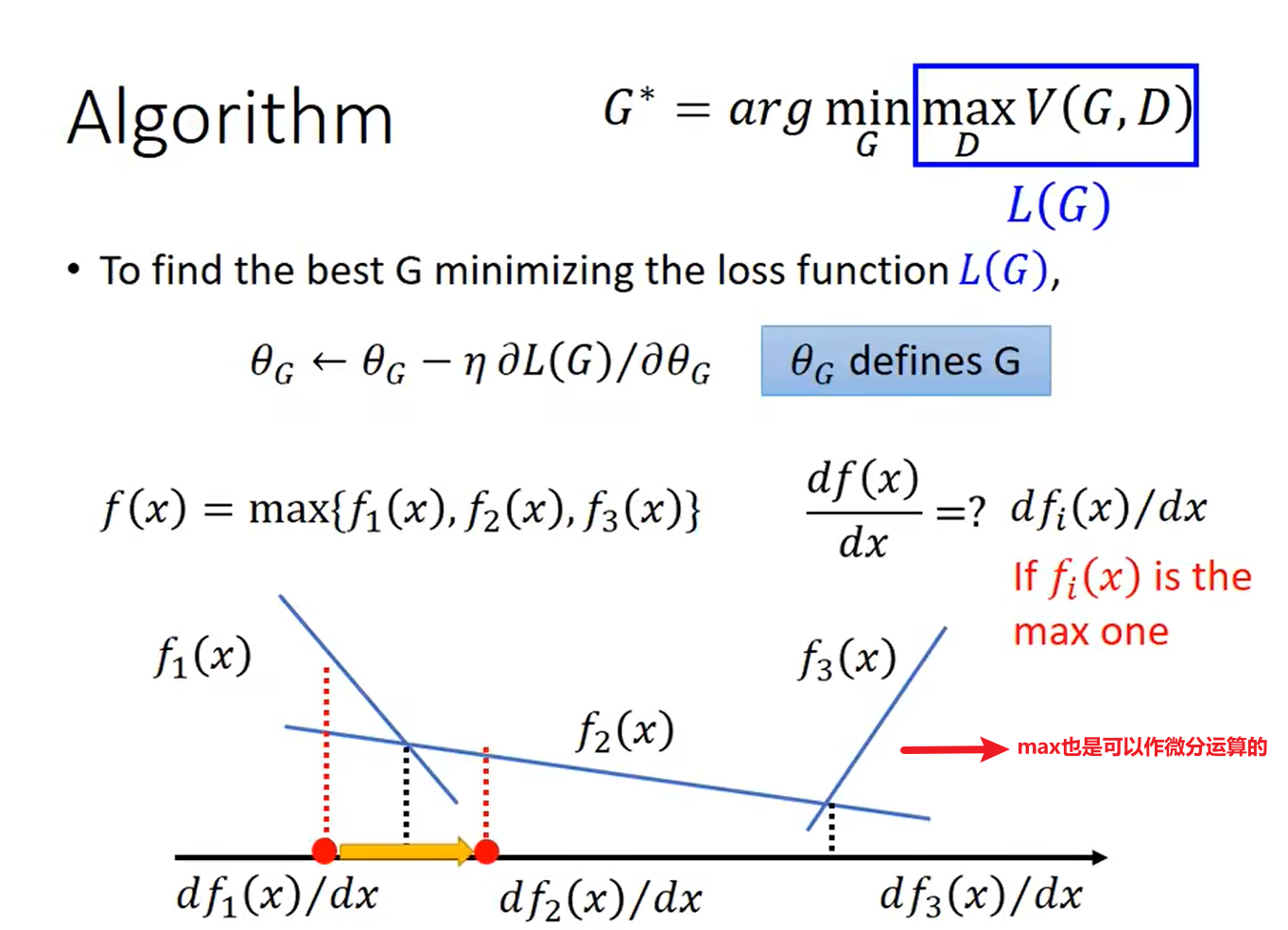
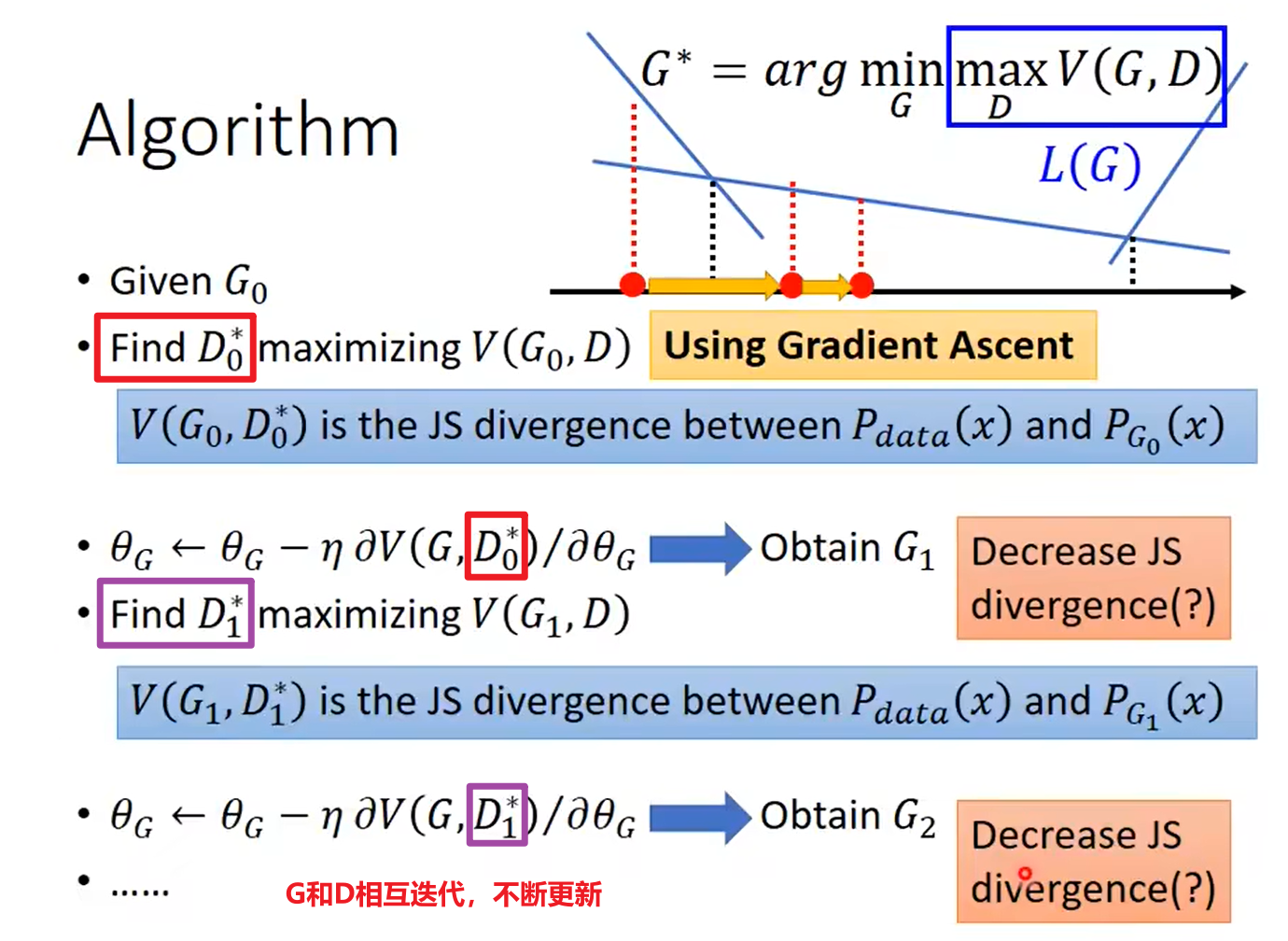
Maximize $\tilde{V}$ = Minimize Cross-entropy

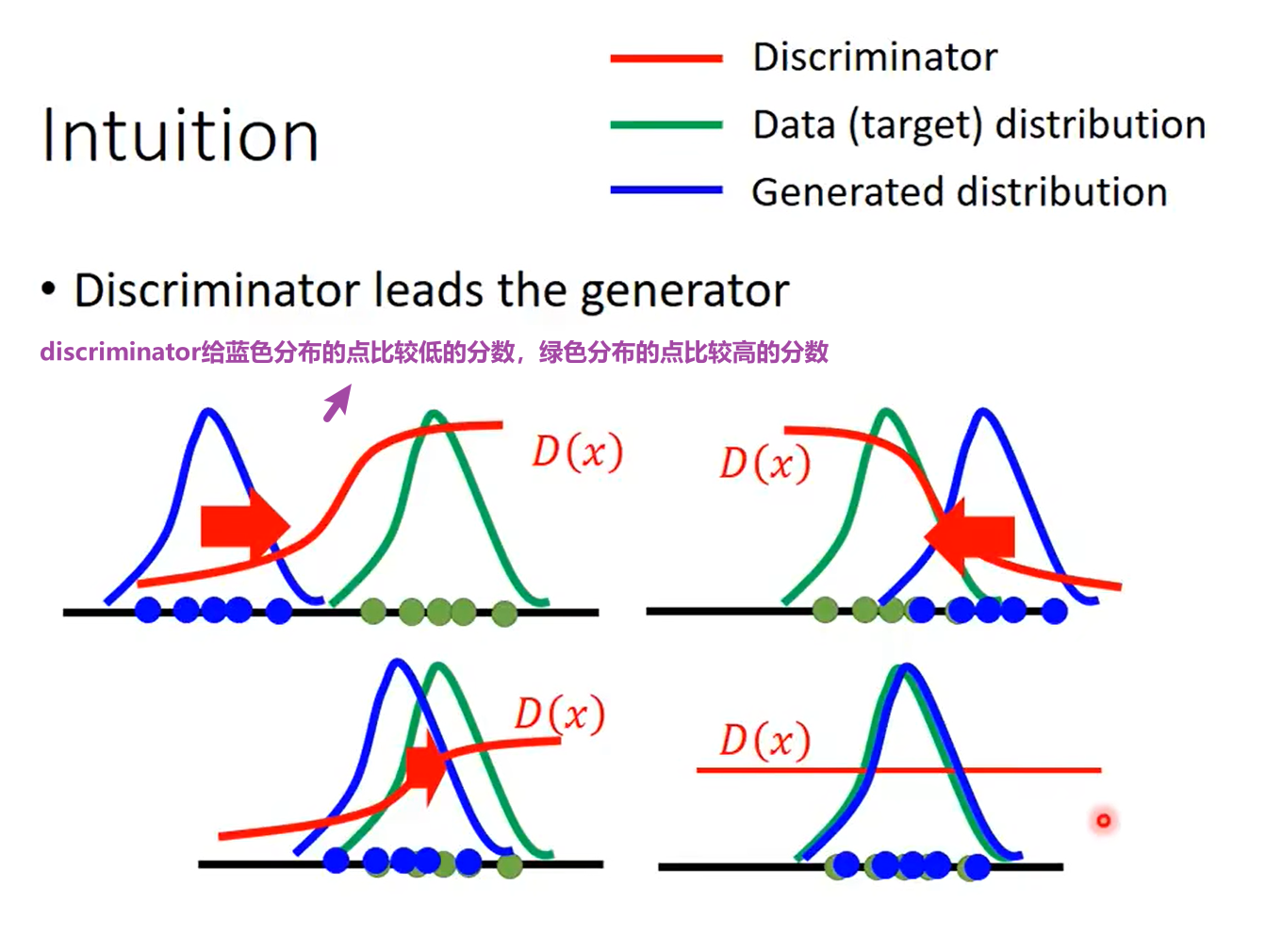
直觉
蓝色分布和绿色分布不断靠近
pytorch代码
1 | import argparse |
代码运行之后的结果展示:

有关train GAN的一些tips

DCGAN: Deep Convolutional Generative Adversarial Network
博客内容
Convolutions+GANs=Good for generating images
DCGAN changed that by using something called a transposed convolution operation or, its “unfortunate” name, Deconvolution layer,.
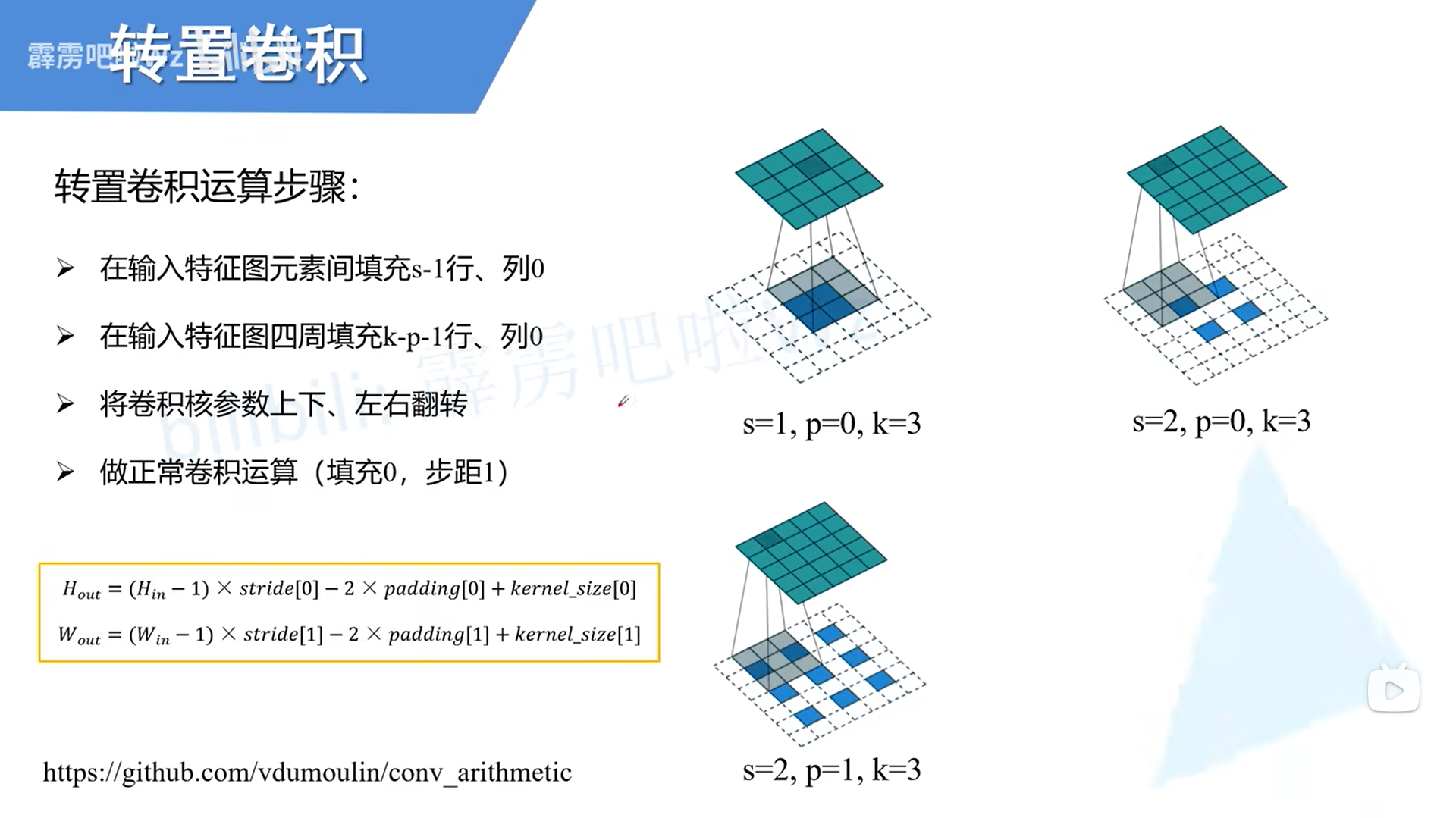
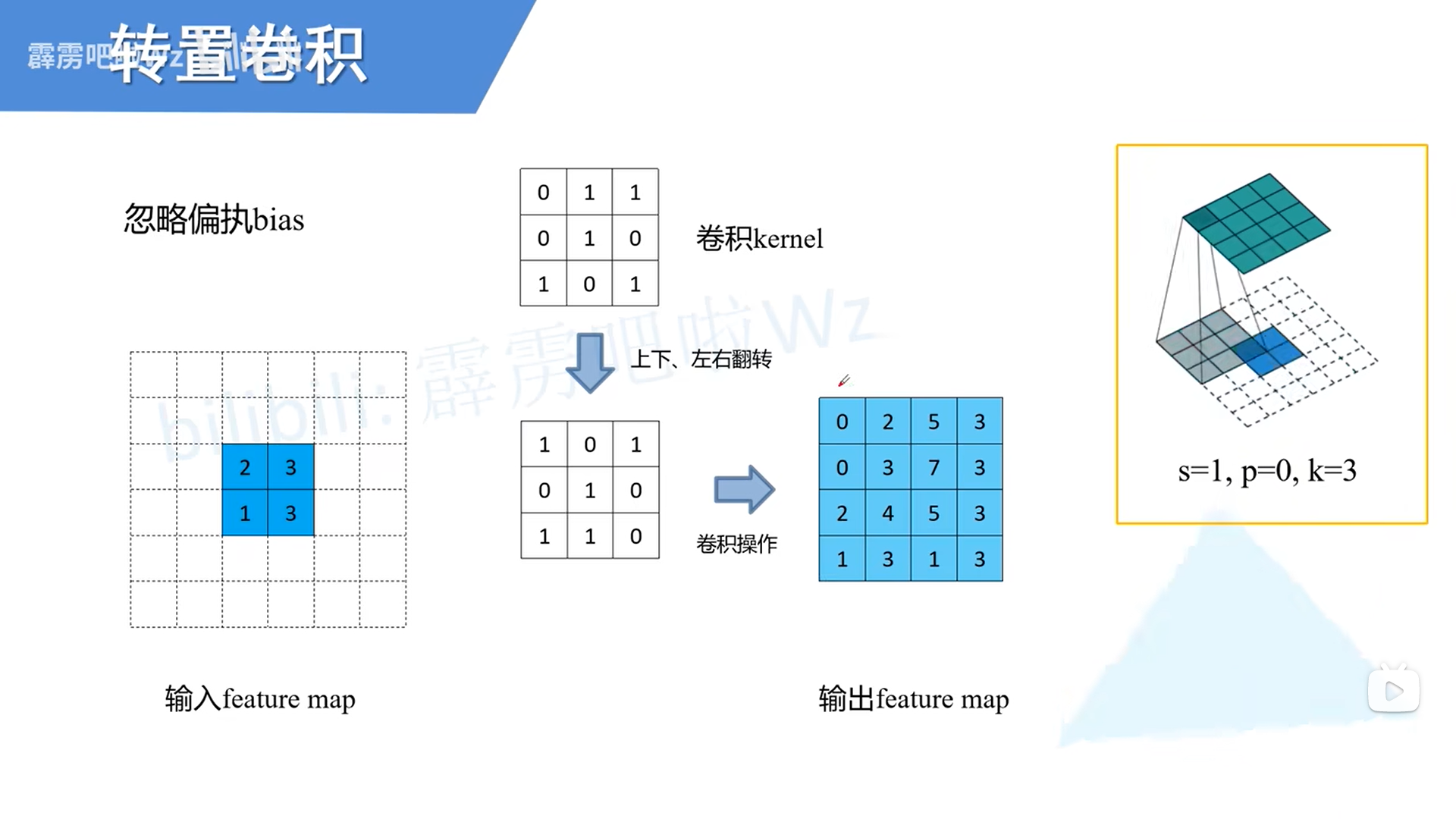
转置卷积不是卷积的逆运算,起上采样作用。
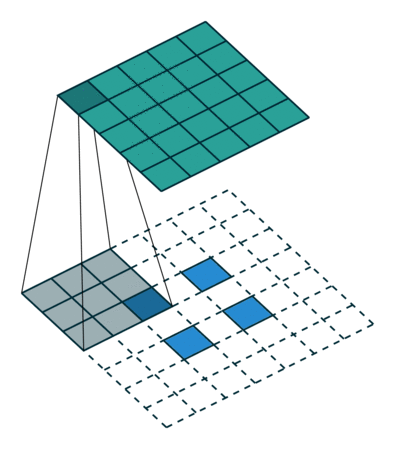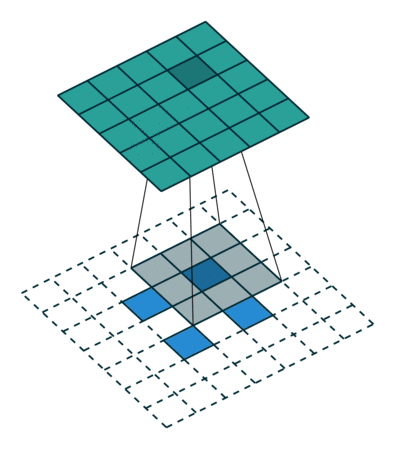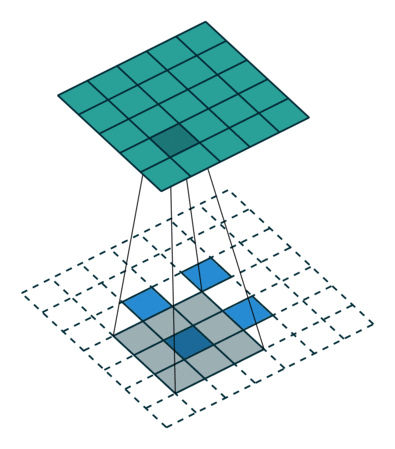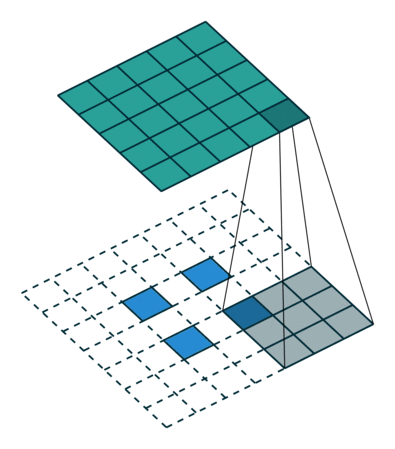
https://blog.csdn.net/LoseInVain/article/details/81098502
https://www.bilibili.com/video/BV1mh411J7U4

要点
- 卷积模块缩减数据,同样配置的转置卷积模块可以抵消这种缩减。因此,转置卷积是生成网络的理想选择。
- 转置卷积卷积核在中间网格上以步长1移动,这个步长是固定的。不同于一般的卷积,这里的步长选项不用来决定卷积核的移动方式,而只用于设置原始方格在中间网格中的距离。
- 转置卷积中加入补全,与普通的卷积不同,之前补全的作用是扩展图像。在这里,补全的作用是缩小图像。
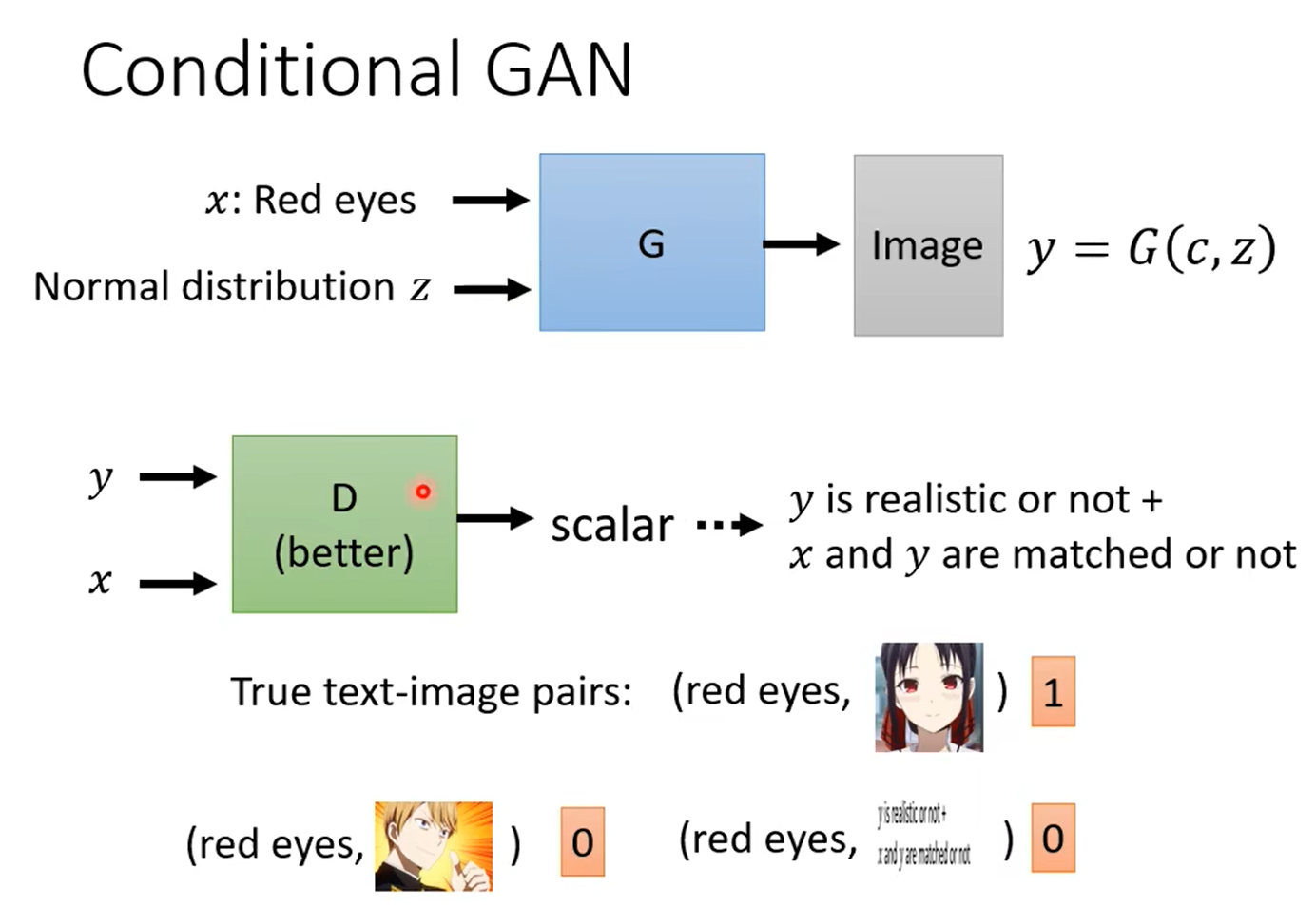
CGAN: Conditional Generative Adversarial Network
要点
- 不同于GAN,条件式GAN可以直接生成特定类型的输出。
- 训练条件式GAN,需要将类别标签分别与图像和种子一起输入鉴别器和生成器。
pytorch代码
1 | import argparse |
运行代码的结果如下:

CycleGAN
博客
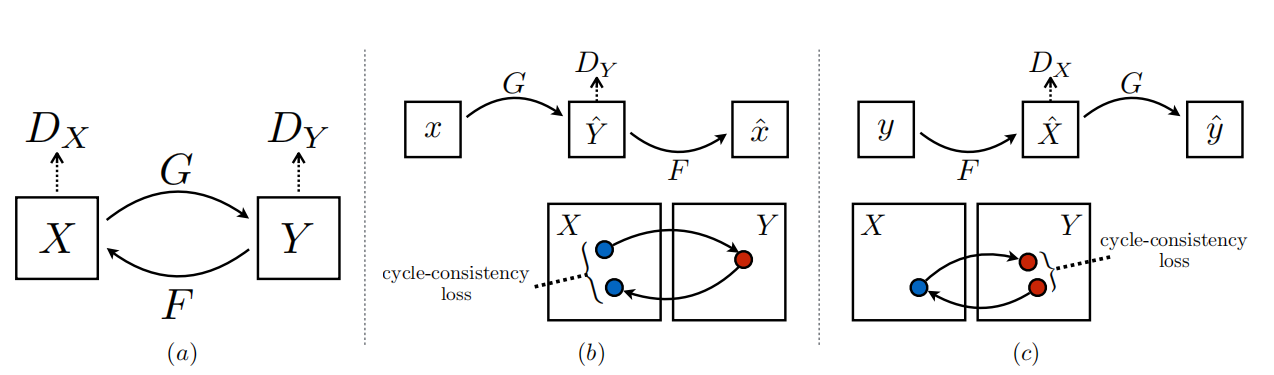
G takes in an image from X and tries to map it to some image in Y. The discriminator $D_Y$ predicts whether an image was generated by G or was actually in Y.
Similarly, F takes in an image from Y and tries to map it to some image in X, And the discriminator $D_X$ predicts whether an image was generated by F or was actually in X.
To further improve performance, CycleGAN uses another metric, cycle consistency loss.
视频参考
https://www.bilibili.com/video/BV1Wv411h7kN?p=61&vd_source=909d7728ce838d2b9656fb13a31483ca
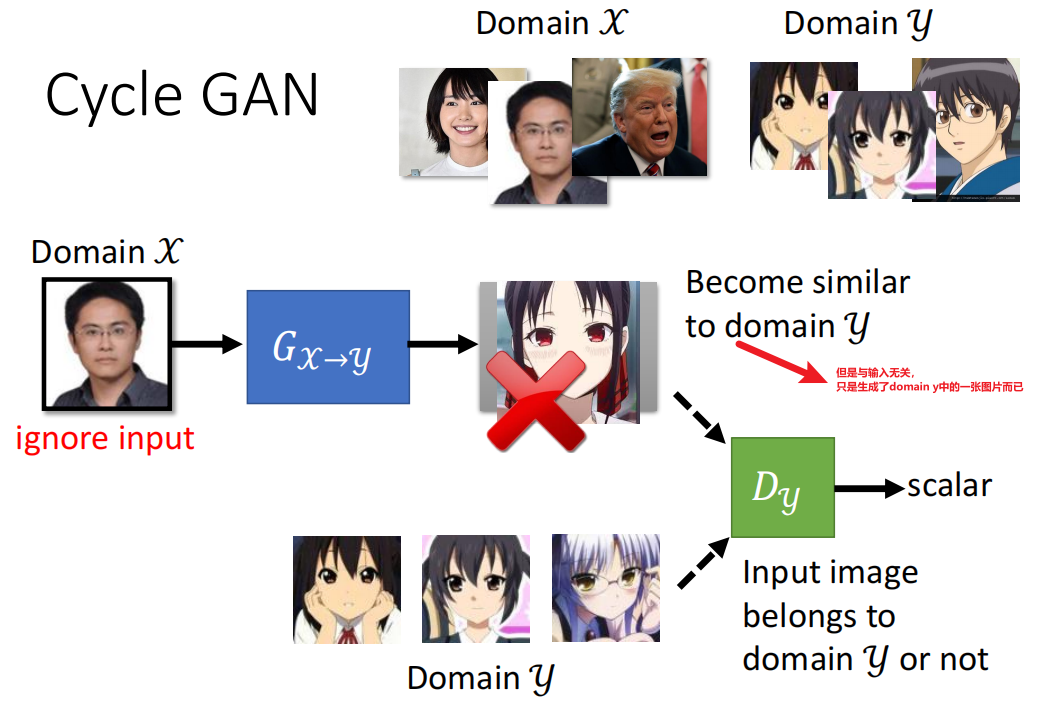
仍然使用原来的GAN可能会无视generator的输入,如下图:
所以就提出了Cycle GAN,结构如下:
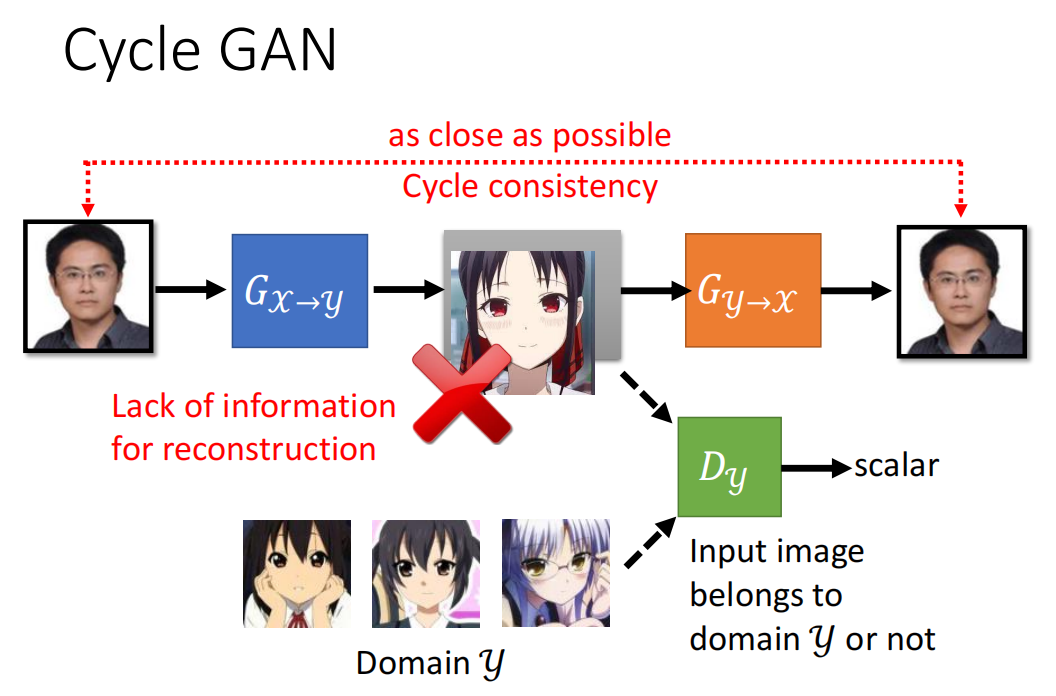
为了让第二个generator能够成功还原原来的图片,第一个generator产生的图片就不能跟输入差太多。
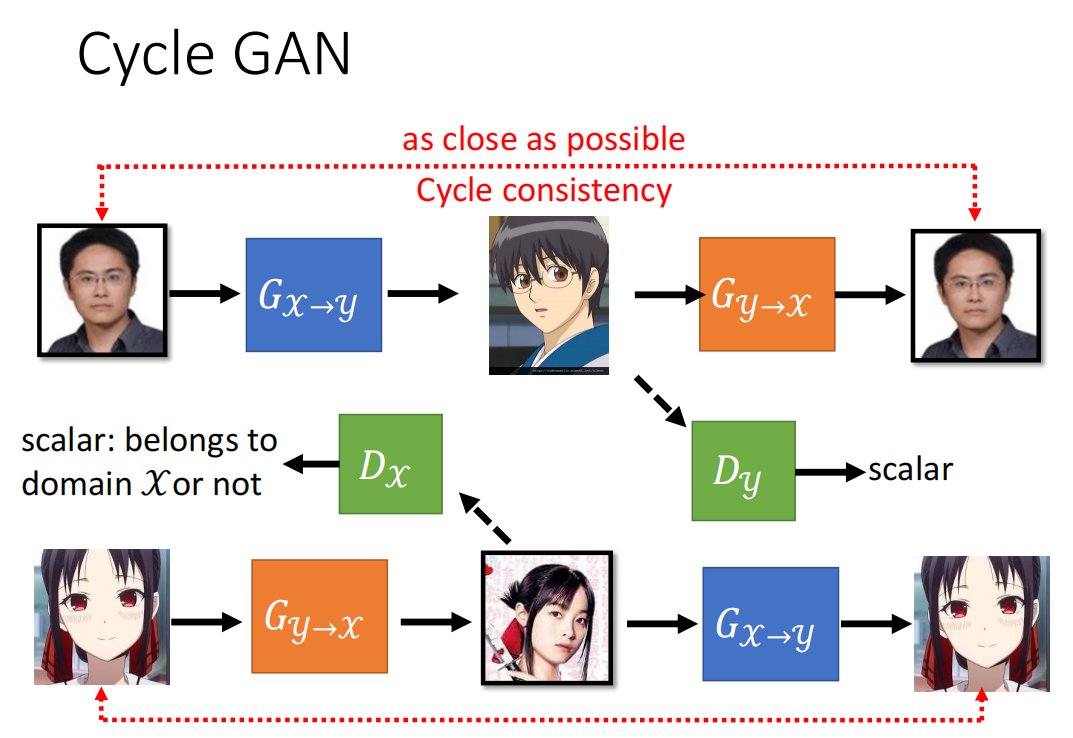
下图为完整的Cycle GAN:
CoGAN
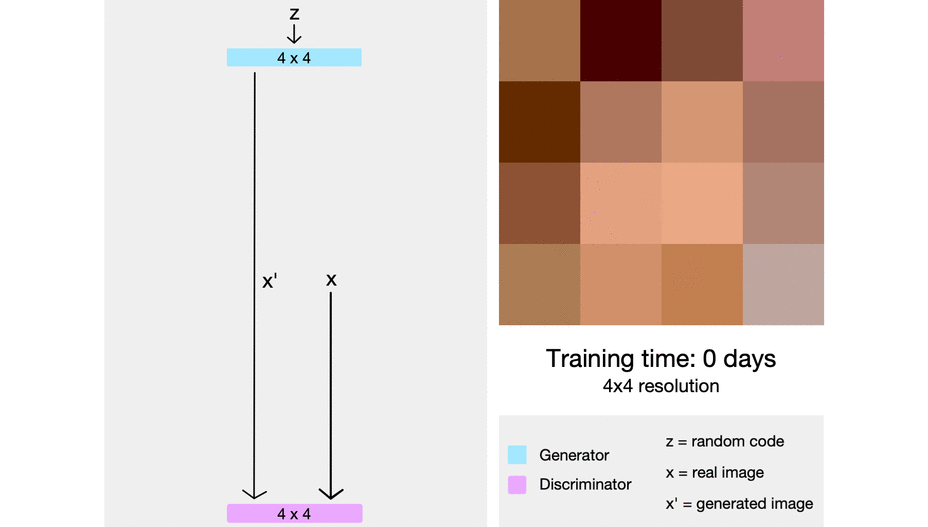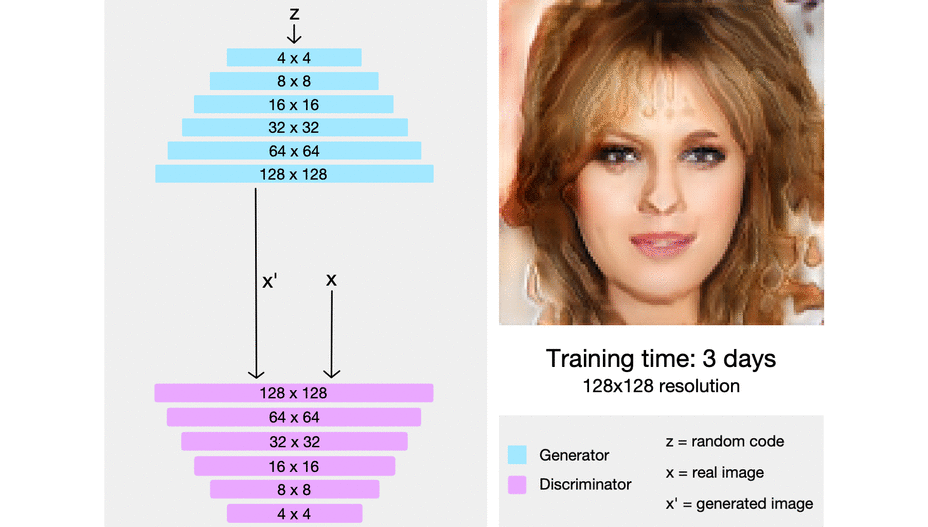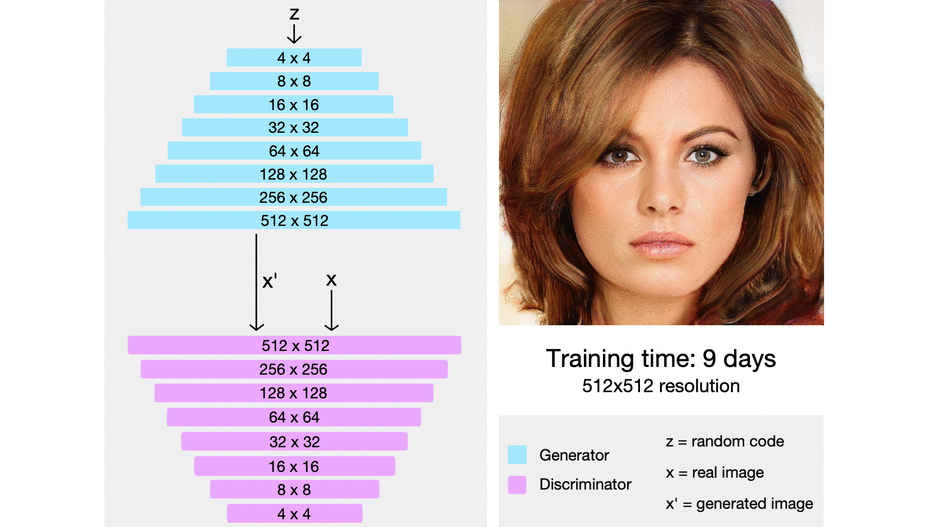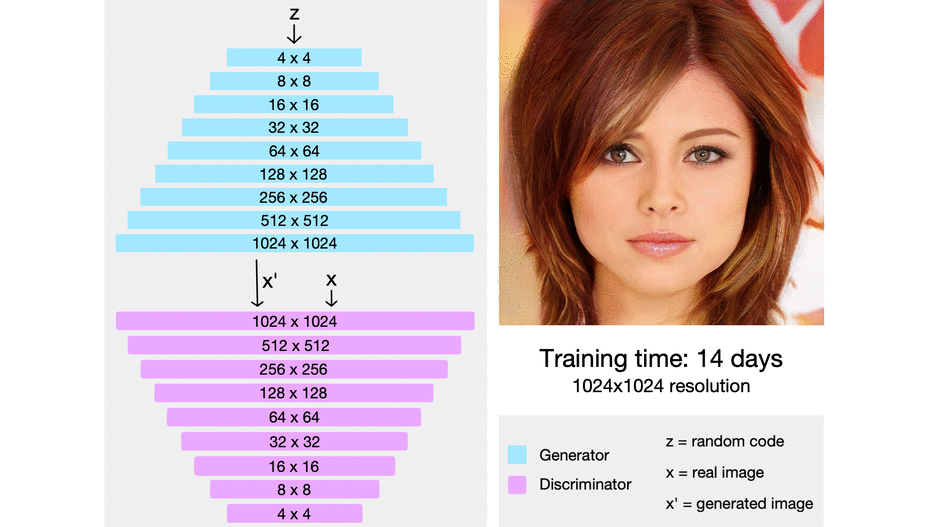
ProGAN: Progressive growing of Generative Adversarial Networks
博客
The intuition here is that it’s easier to generate a 4x4 image than it is to generate a 1024x1024 image. Also, it’s easier to map a 16x16 image to a 32x32 image than it is to map a 2x2 image to a 32x32 image.
WGAN: Wasserstein Generative Adversarial Networks
博客
The Jensen-Shannon divergence is a way of measuring how different two probability distributions are.The larger the JSD, the more “different” the two distributions are, and vice versa.
The alternate distance metric proposed by the WGAN authors is the 1-Wasserstein distance, sometimes called the earth mover distance.
理解JS散度(Jensen–Shannon divergence)
KL散度
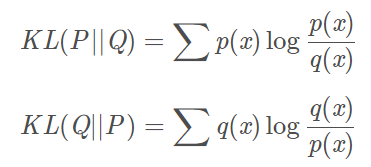
KL散度具有非负性和不对称$KL(P||Q)\ne KL\left( Q||P \right) $。
JS散度
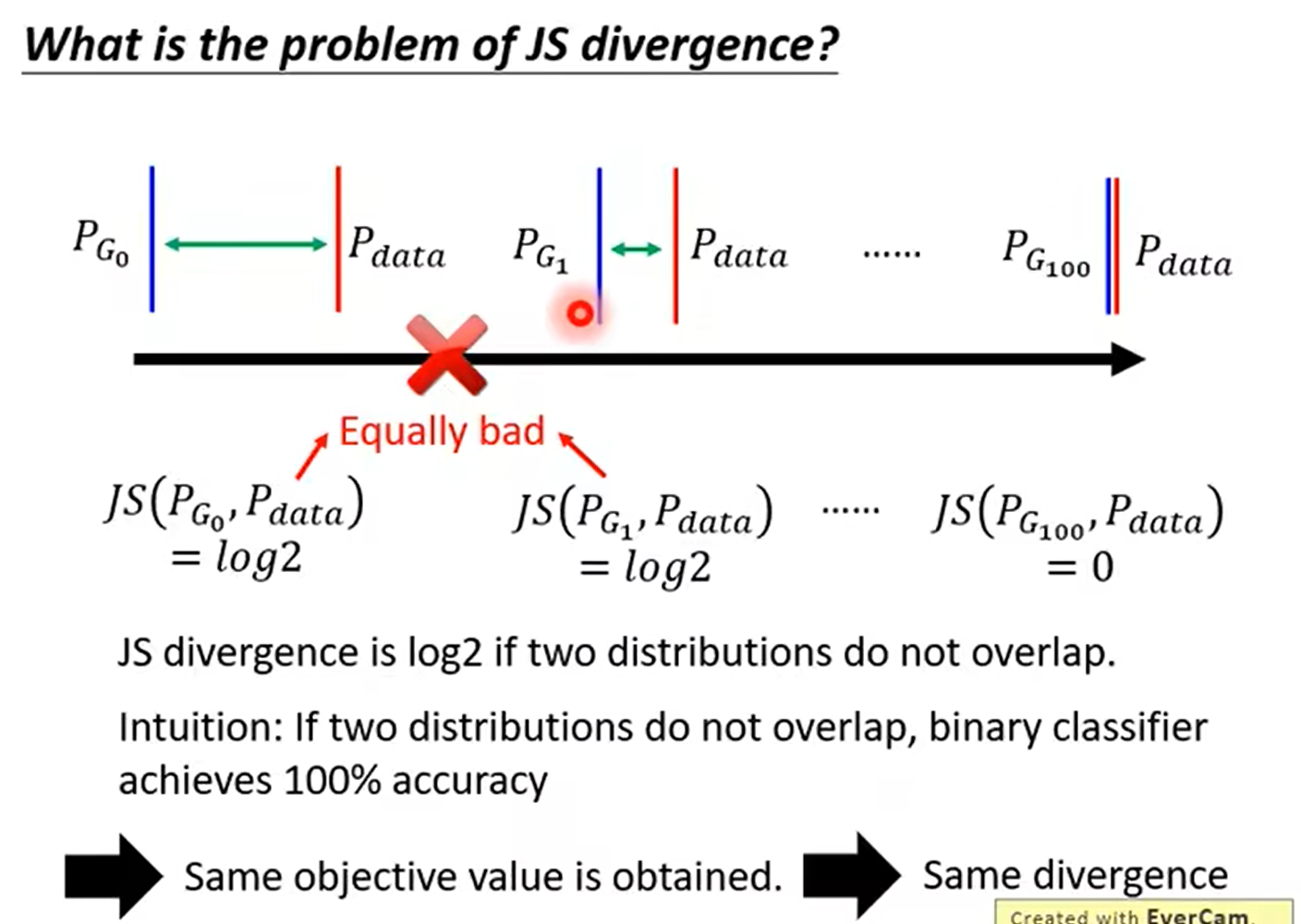
一般地,JS散度是对称的,其取值是 0 到 1 之间。如果两个分布 P,Q 离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味这这一点的梯度为 0。梯度消失了。

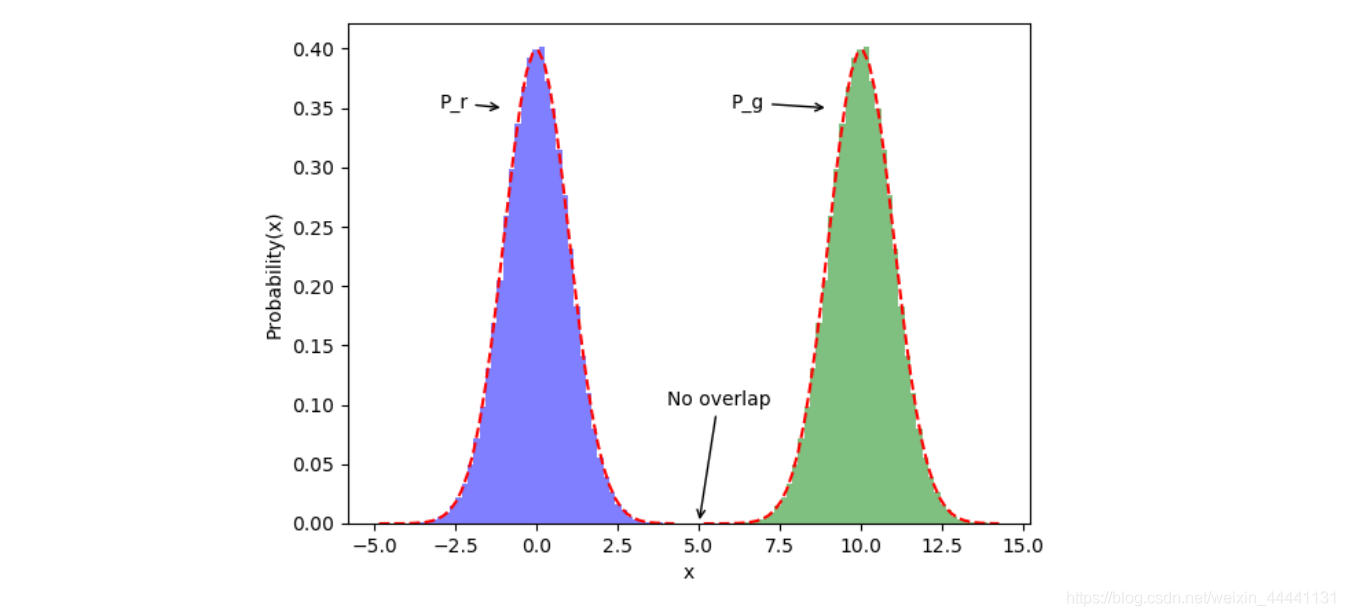

为什么会出现两个分布没有重叠的现象

令人拍案叫绝的Wasserstein GAN
https://zhuanlan.zhihu.com/p/25071913
上面这个博客讲得非常清楚:在第一篇《Towards Principled Methods for Training Generative Adversarial Networks》里面推了一堆公式定理,从理论上分析了原始GAN的问题所在,从而针对性地给出了改进要点;在这第二篇《Wasserstein GAN》里面,又再从这个改进点出发推了一堆公式定理,最终给出了改进的算法实现流程,而改进后相比原始GAN的算法实现流程却只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
视频参考
https://www.bilibili.com/video/BV1Wv411h7kN?p=64&vd_source=909d7728ce838d2b9656fb13a31483ca
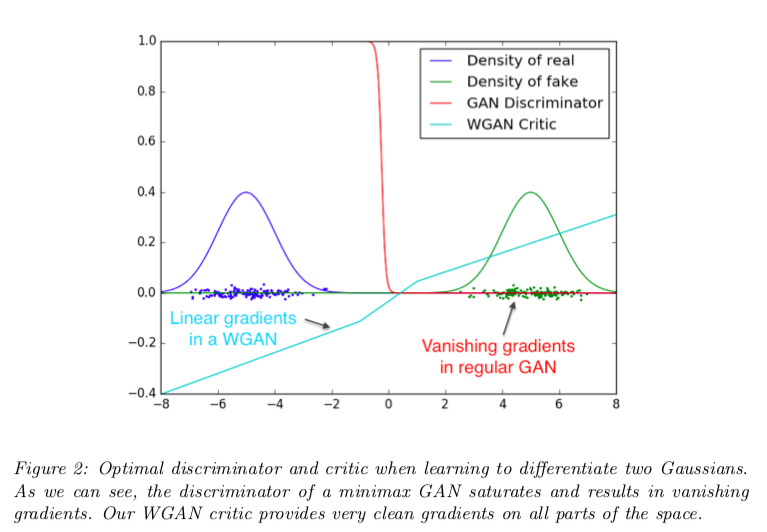
JS divergence存在着如下的问题:
earth mover distance的定义如下:
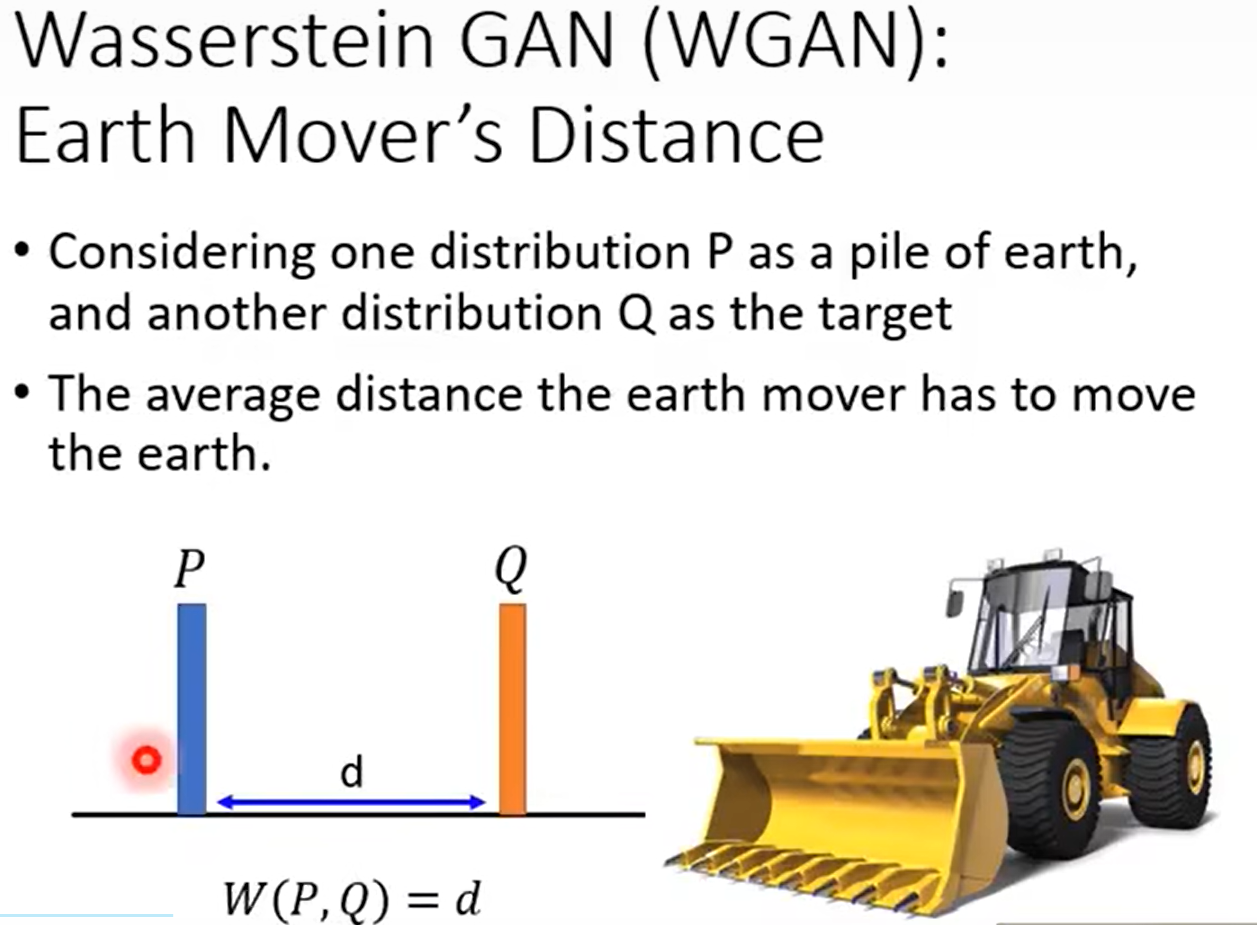
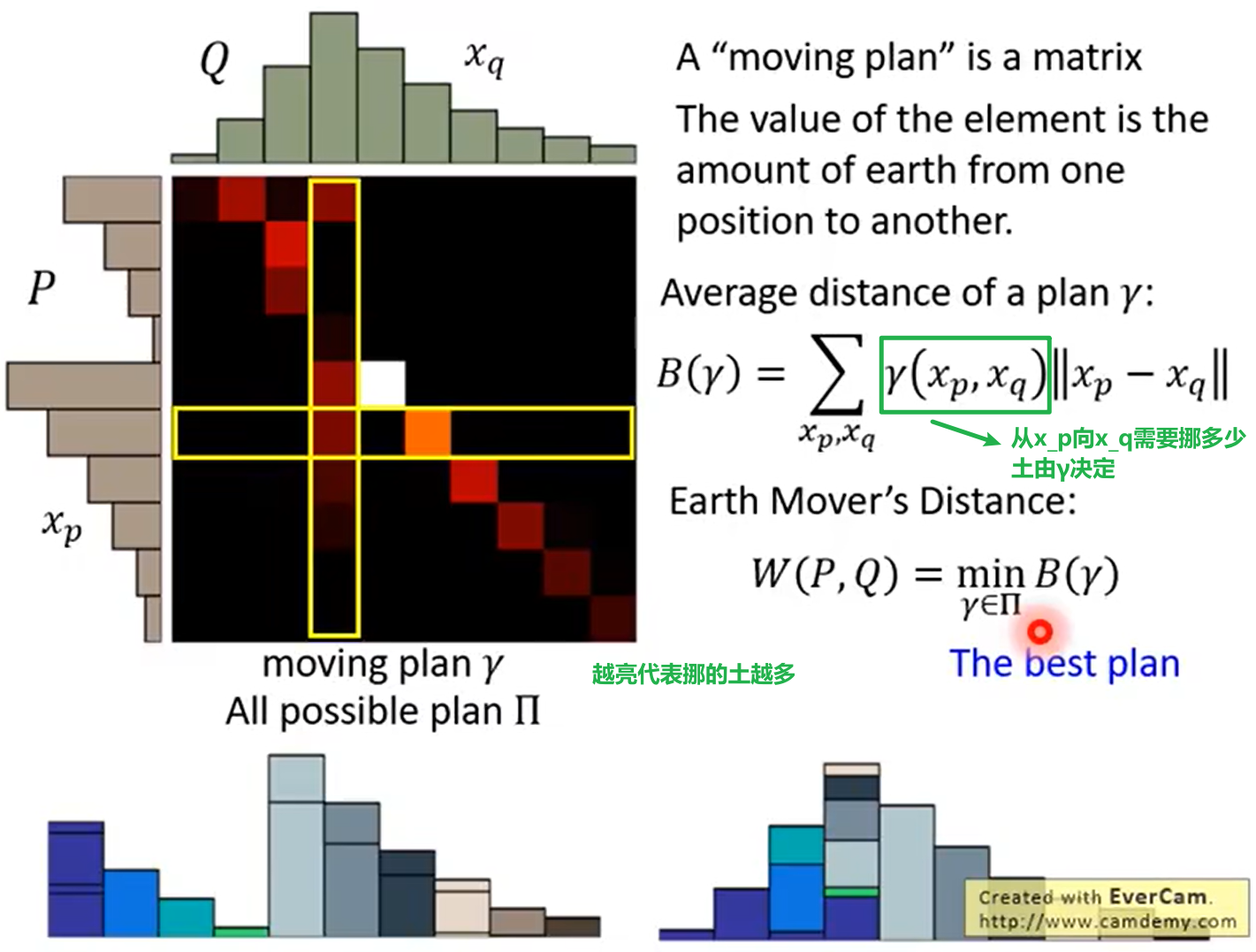
中间推导过程省略,直接给出$P_{data}$和$P_G$之间的Wasserstein distance如何计算

Lipschitz Function的直观理解:input有变化时,output的变化不会太大。
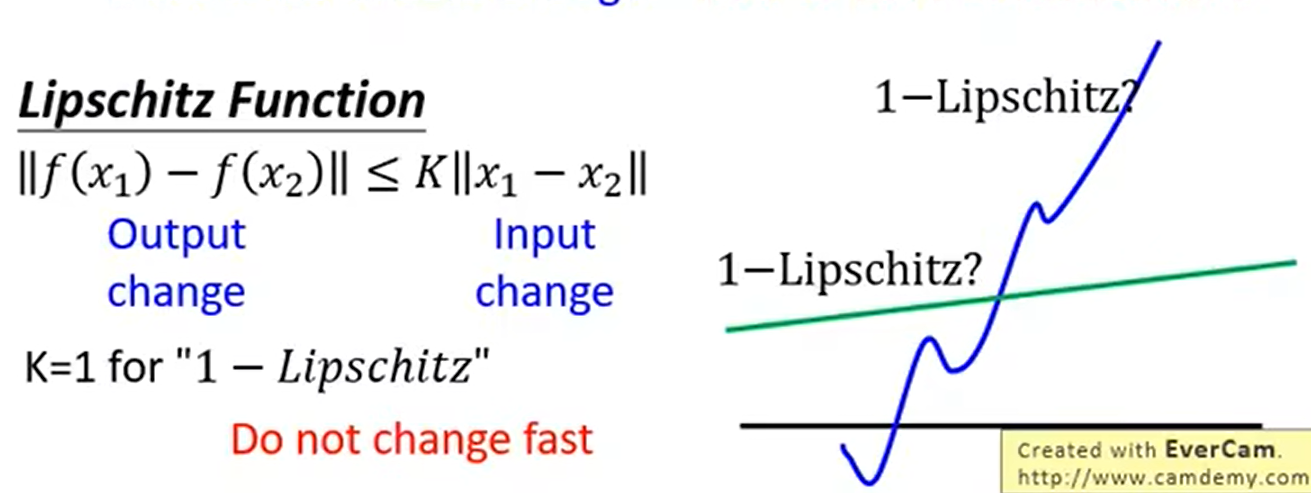
How to fulfill this constraint?→Weight Clipping

WGAN的训练步骤:

SAGAN: Self-Attention Generative Adversarial Networks
博客
Since GANs use transposed convolutions to “scan” feature maps, they only have access to nearby information.
Self-attention allows the generator to take a step back and look at the “big picture.”
BigGAN
博客
The authors also train BigGAN on a new dataset called JFT-300, which is an ImageNet-like dataset which has, you guessed it, 300 million images. They showed that BigGAN perform better on this dataset, suggesting that more massive datasets might be the way to go for GANs
StyleGAN: Style-based Generative Adversarial Networks
博客
StyleGAN is like a photoshop plugin, while most GAN developments are a new version of photoshop.
有关GAN的参考书籍







自 强 不 息

QQ邮箱:2233134941@qq.com


