
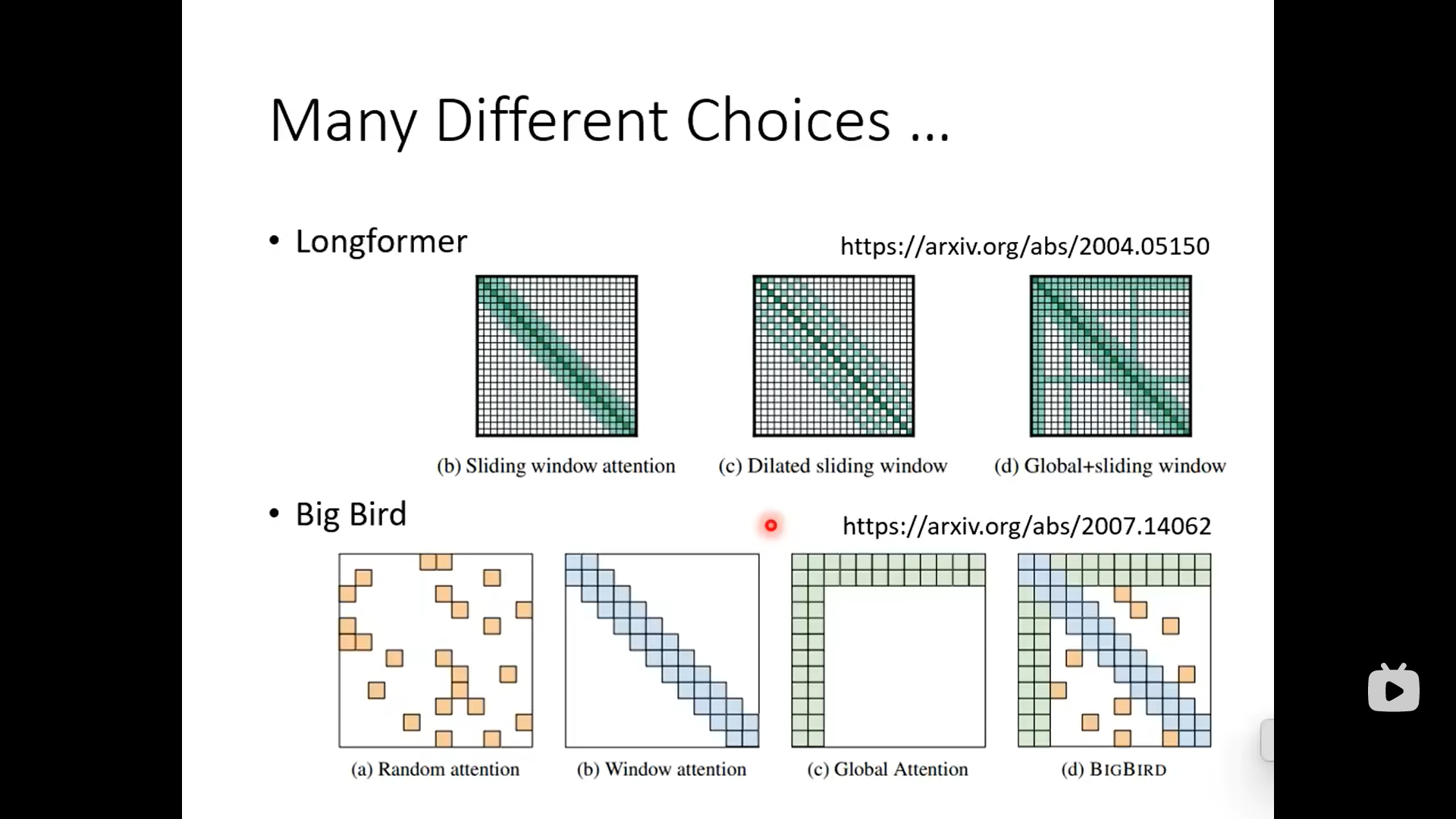
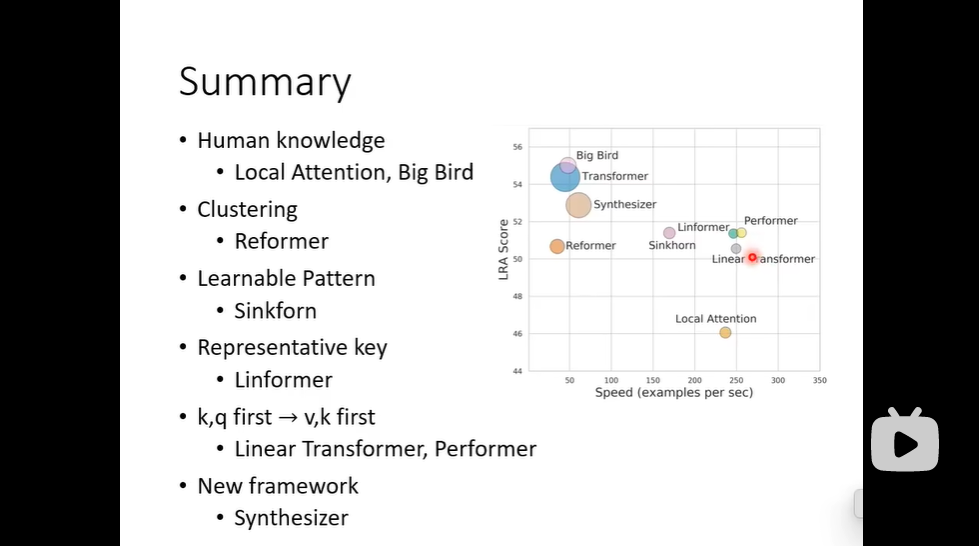
各式各样的自注意力机制
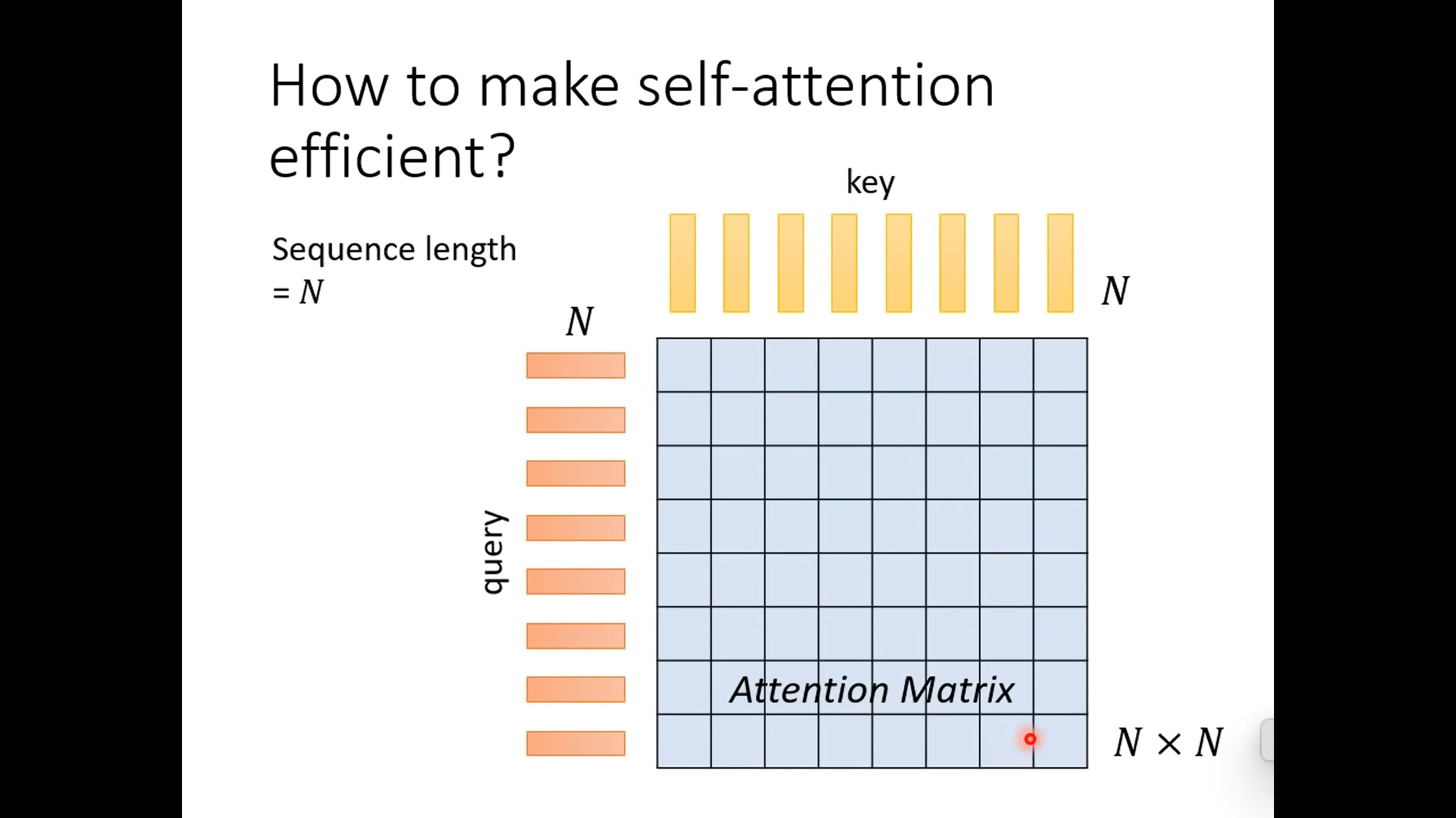
对于图片来说,N是很大的,所以计算量会很大


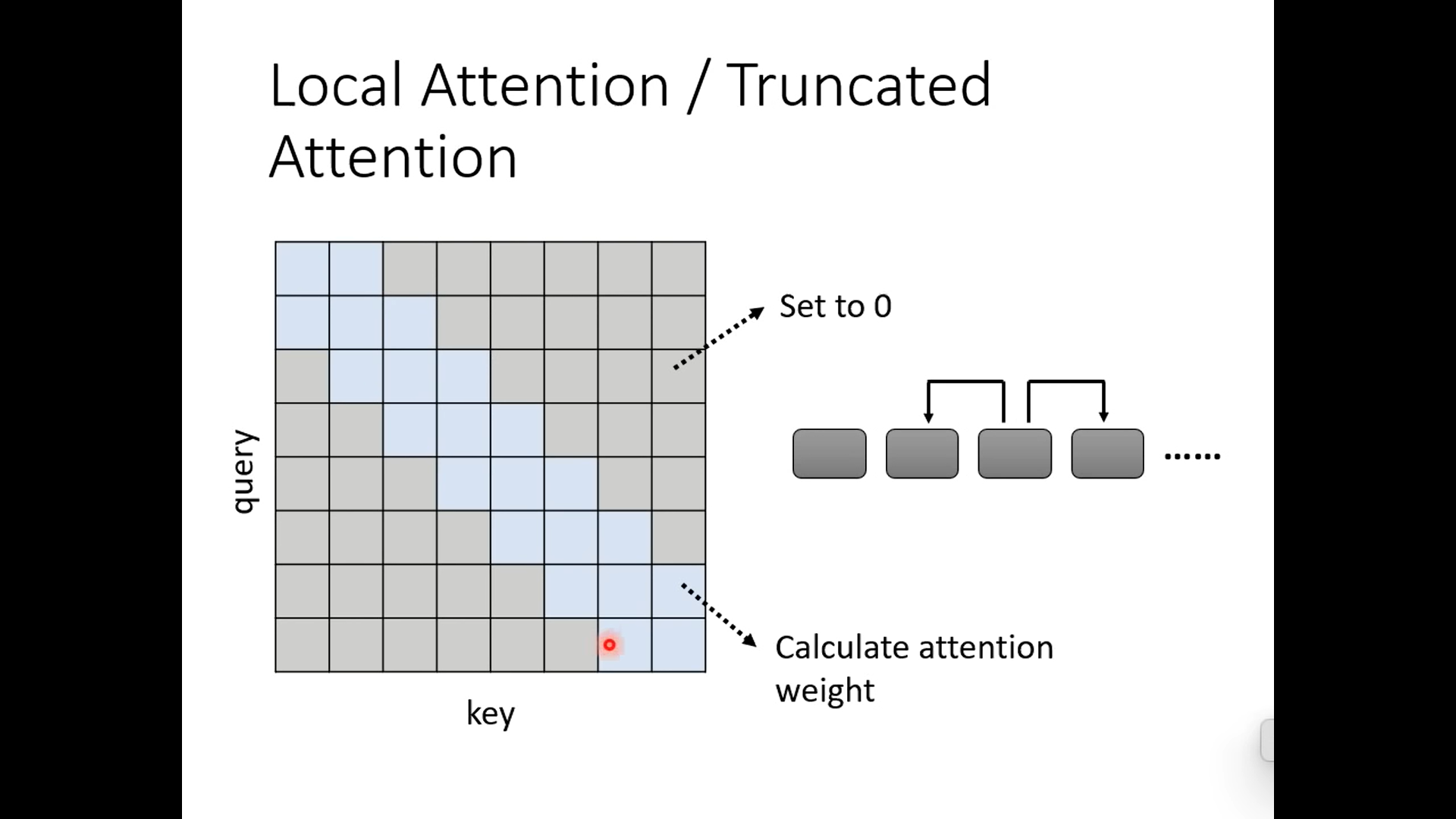
下面这种方式是关注临近的
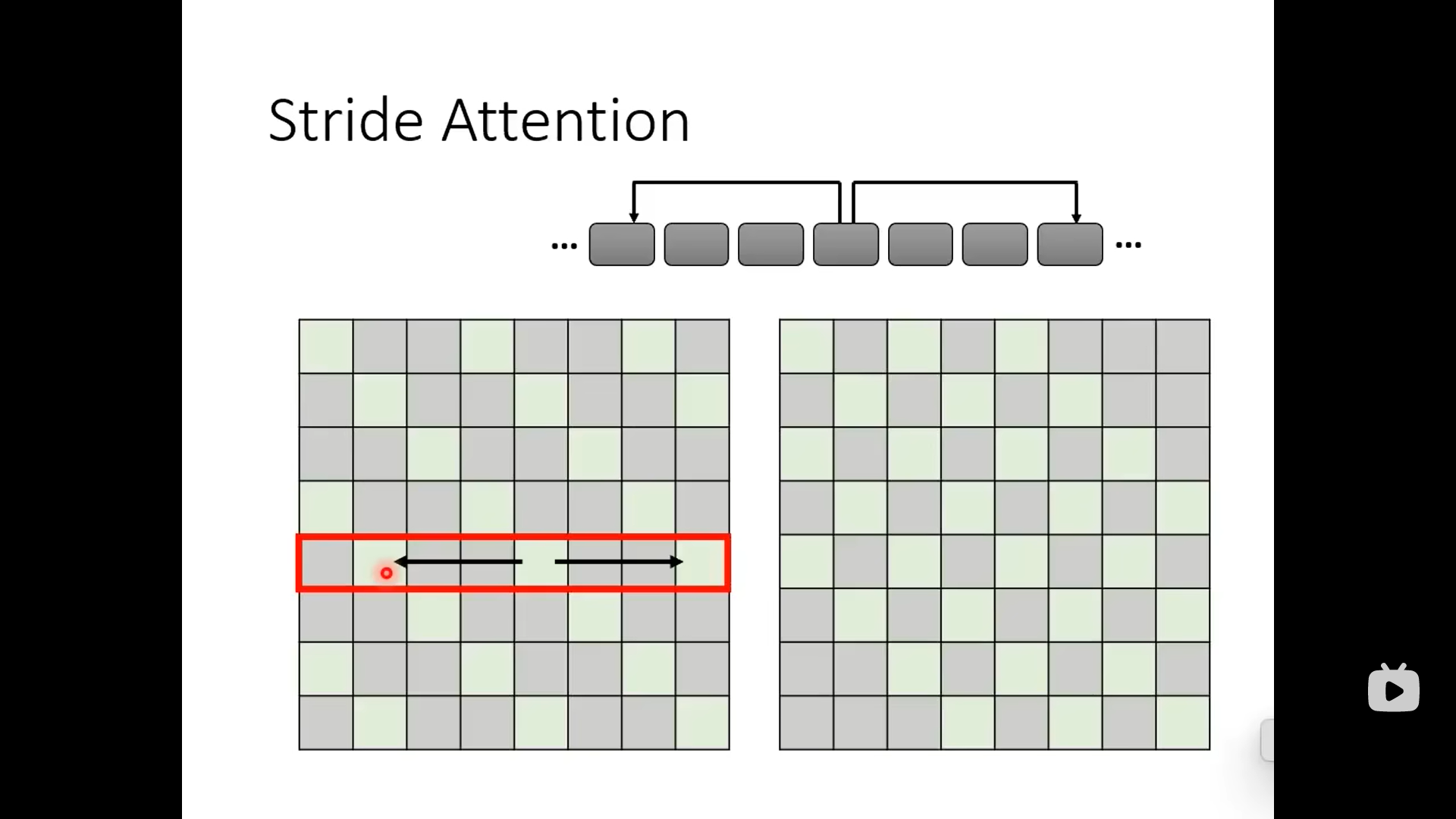
下面这个是关注的稍微远一点,中间跨几个:
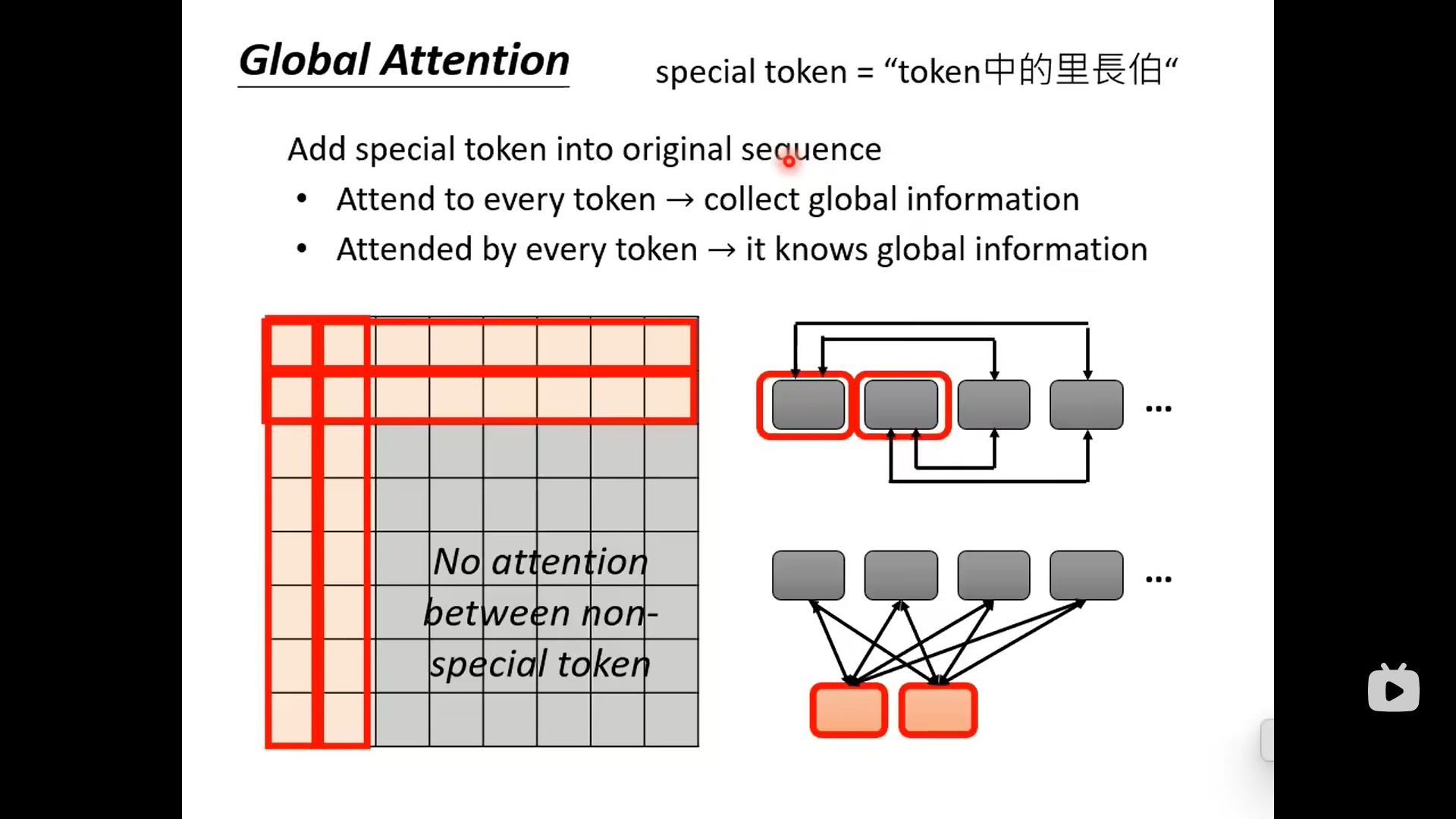
下面的是设置几个special的token,让这几个token去收集global的information。
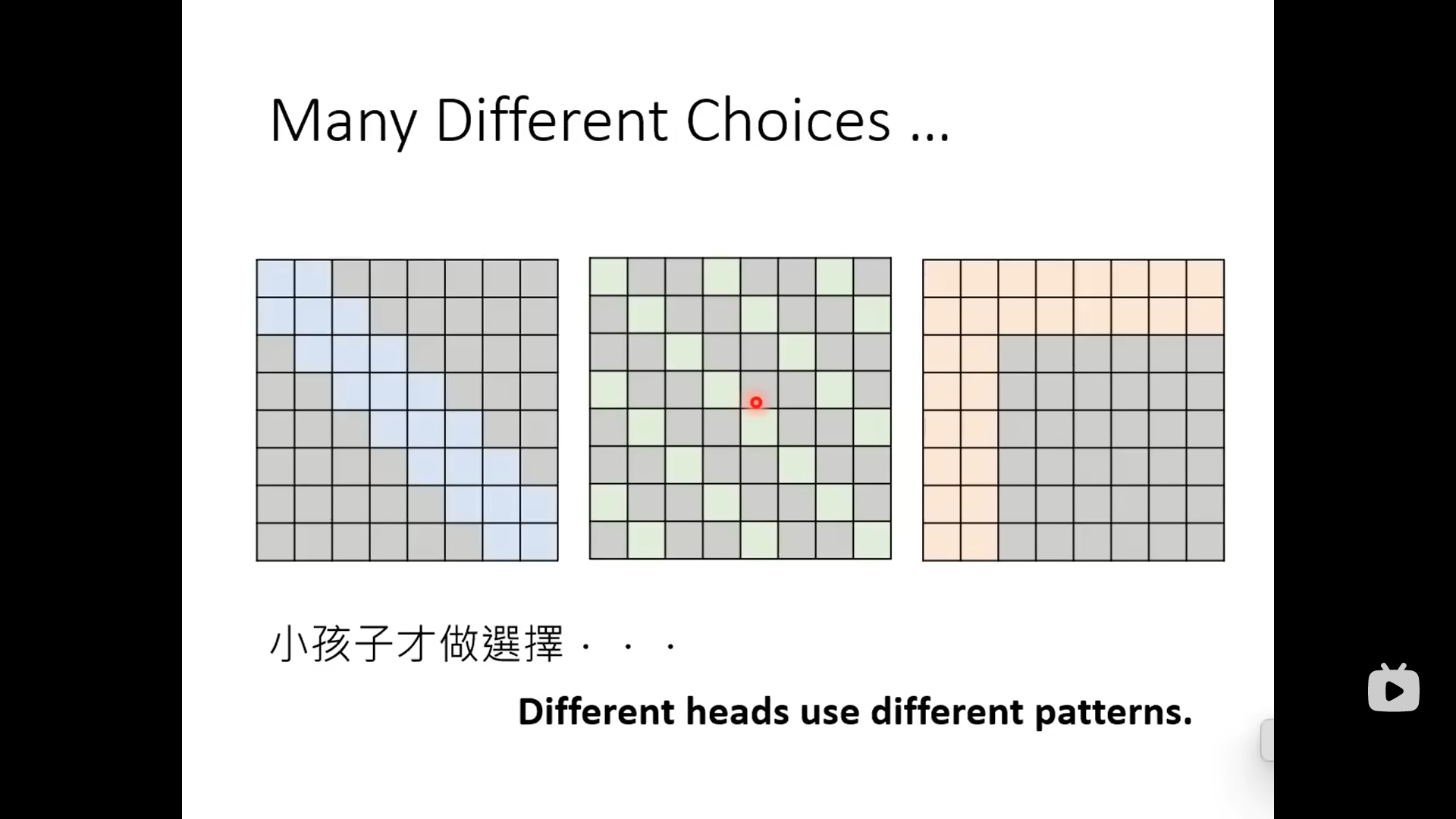
小孩子才做选择,上面三种一起上(多头注意力)

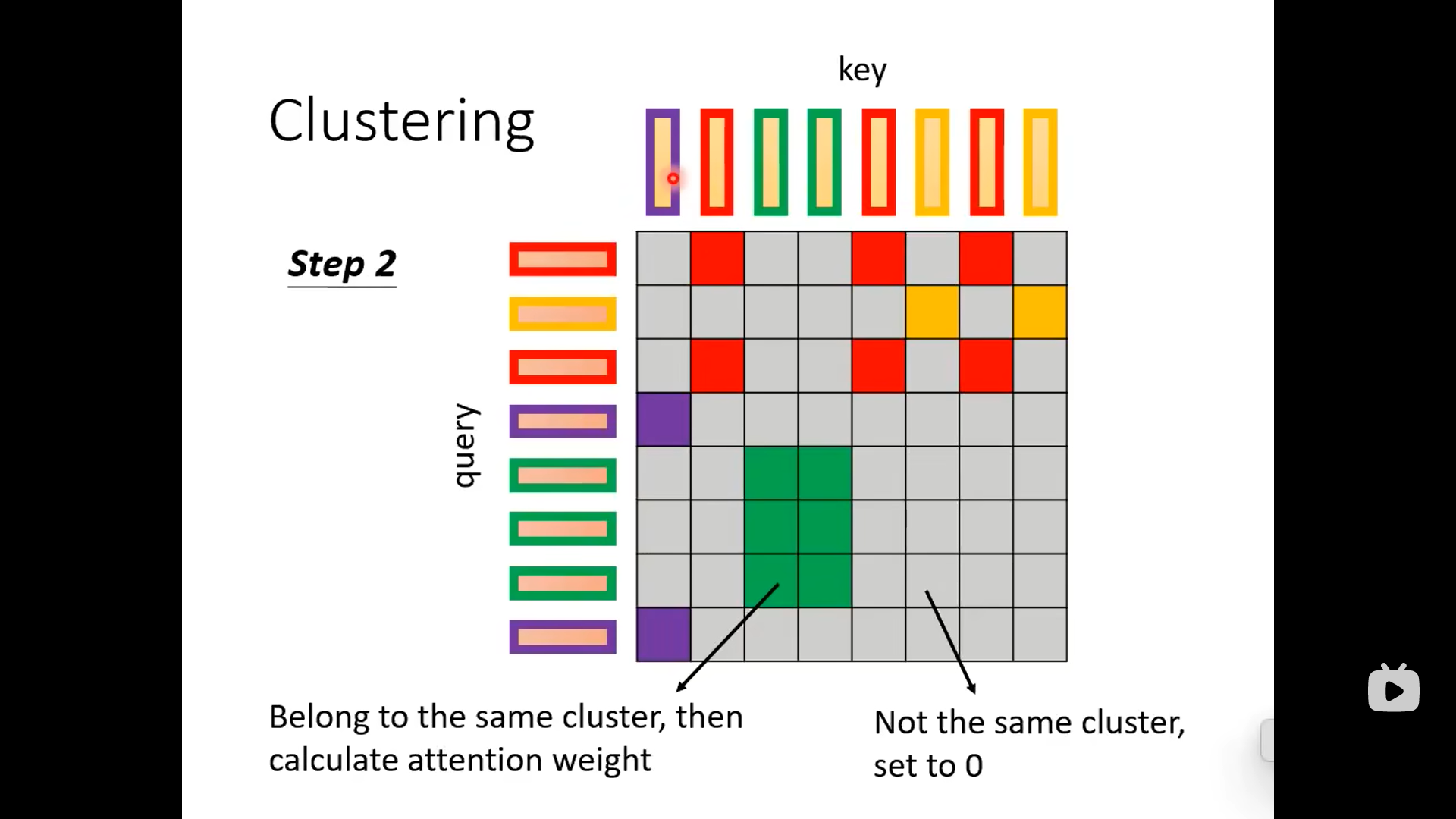
下面这种方法先把相近的query和key归到同一类里面:

上面这些方式都是人为设计的,下面是机器自己决定到底关注哪些重要部分,蓝色是1,灰色是0,通过另一个网络先得到一个的矩阵,但是这个矩阵里面的值都是连续的,需要经过一系列操作之后才能变成binary的mask。

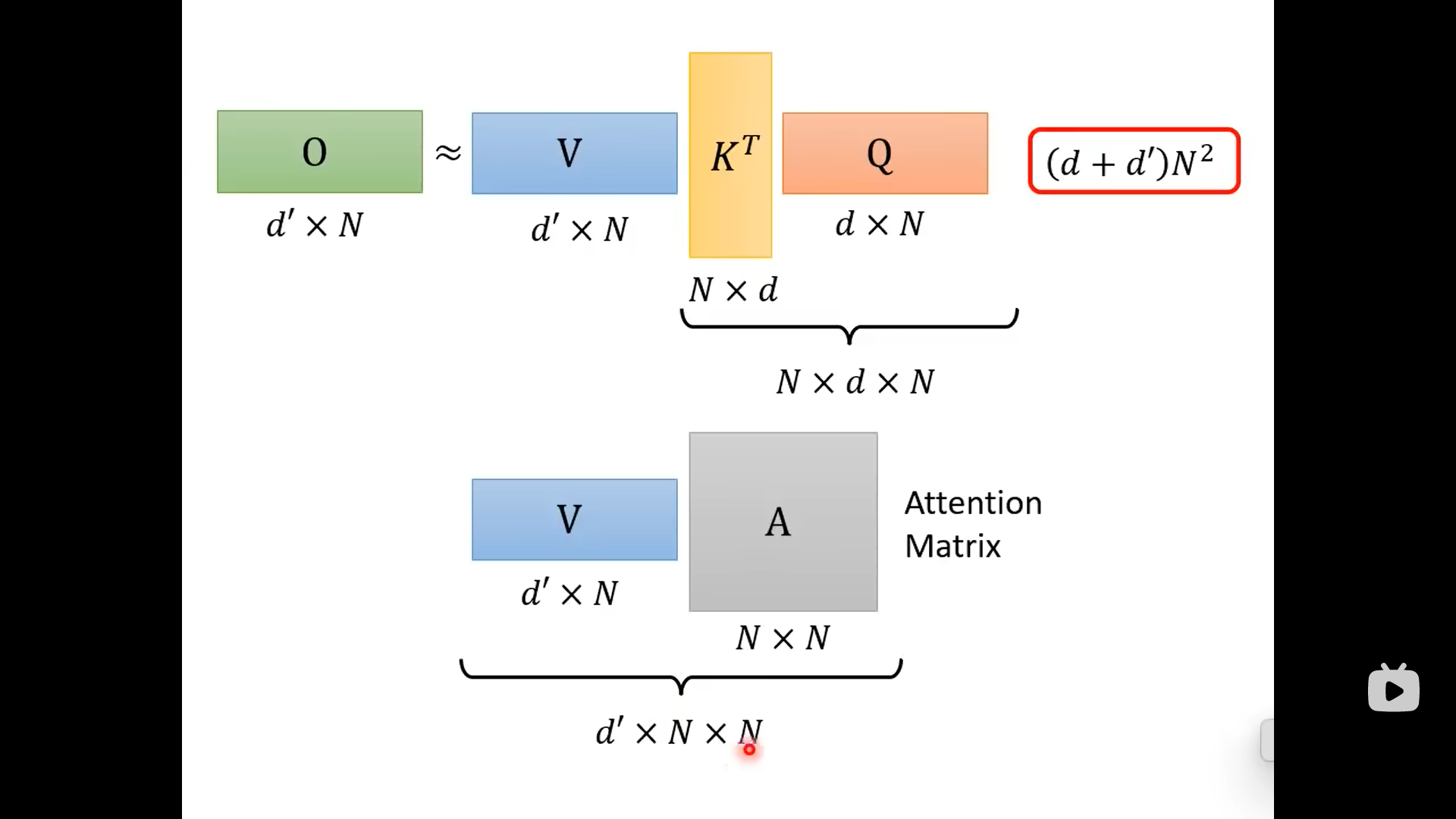
有的研究发现,attention的矩阵是low rank的,它的column有很多重复的,所以attention的matrix可以不那么大,如右图所示
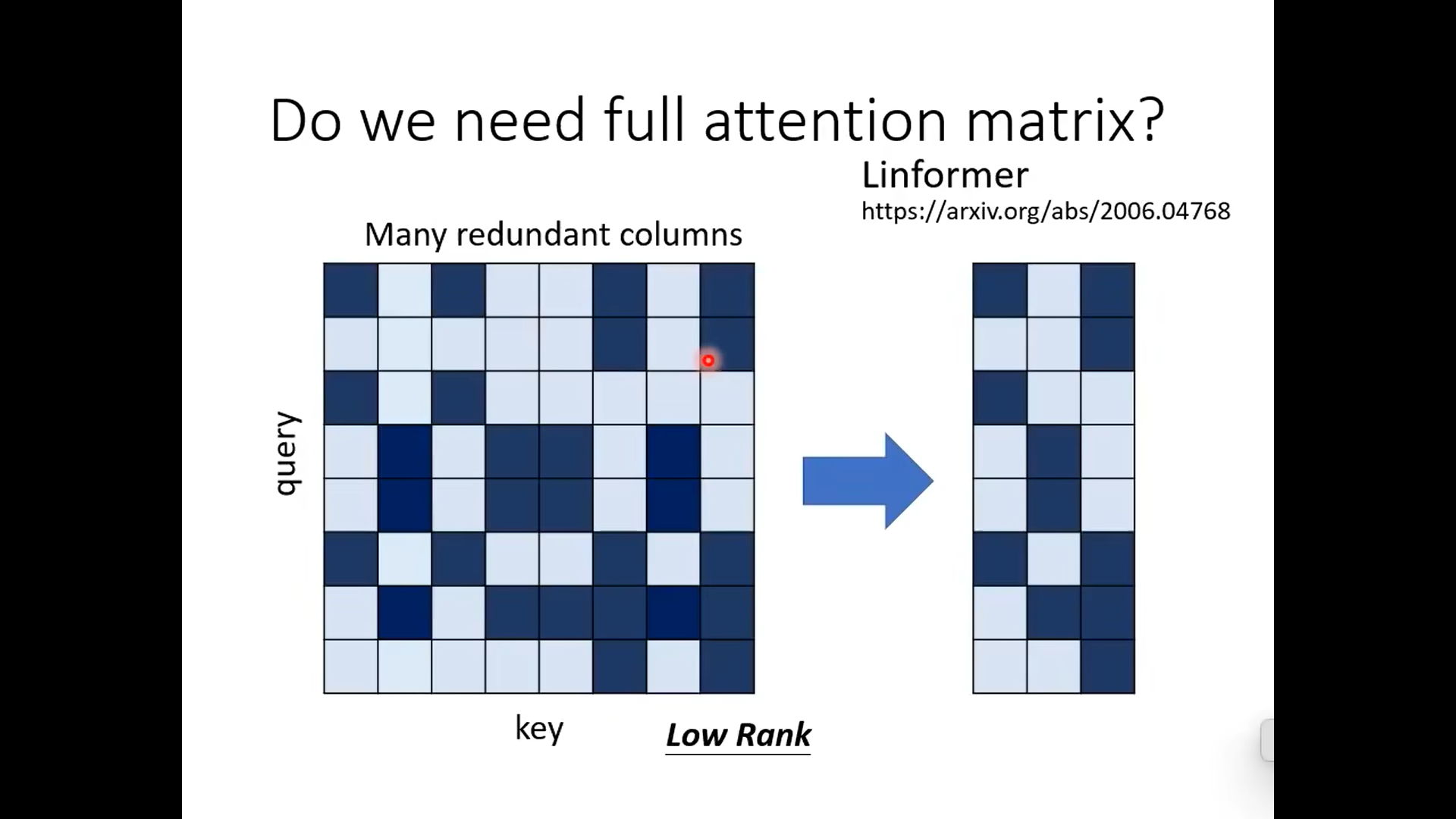
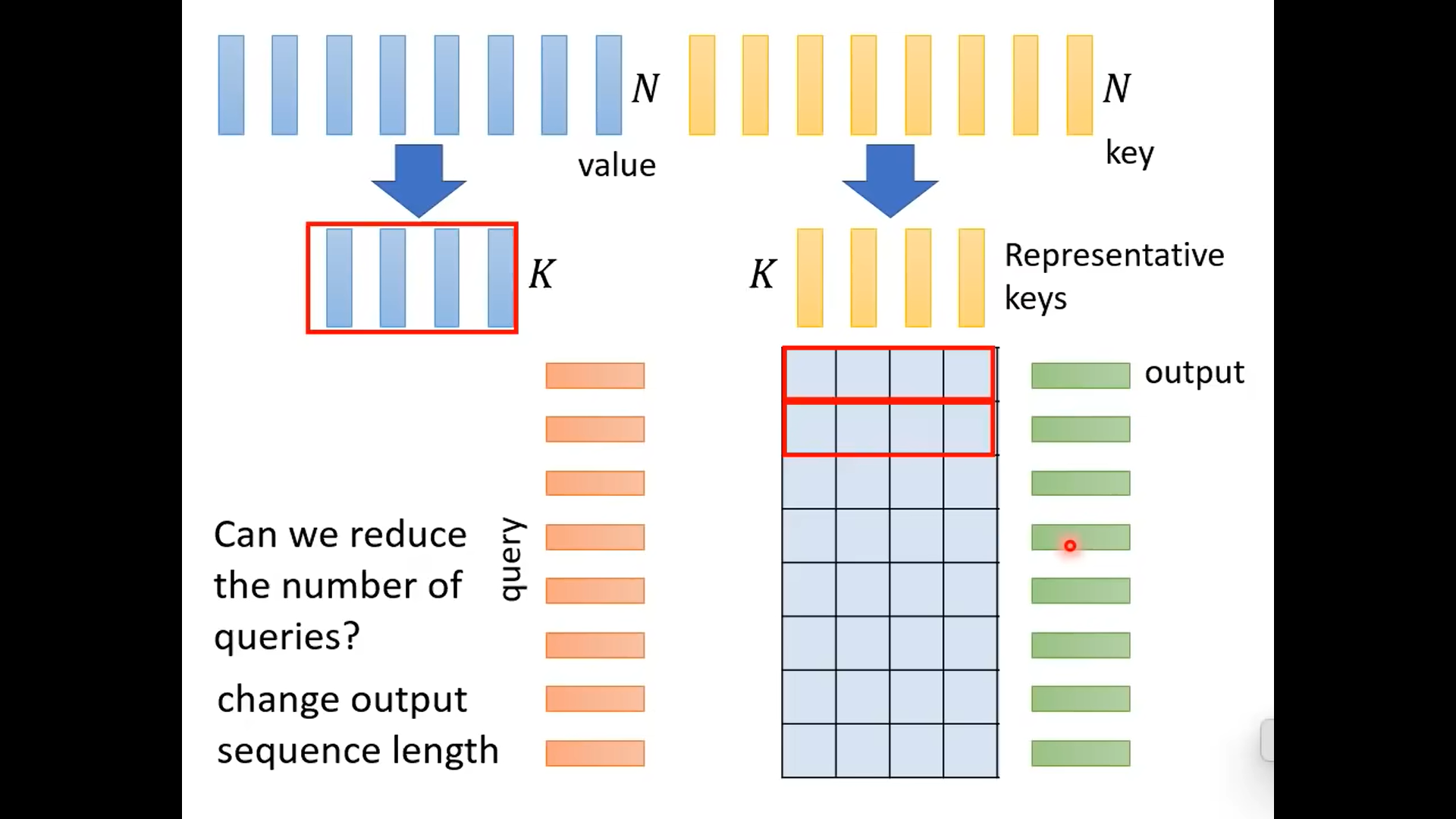
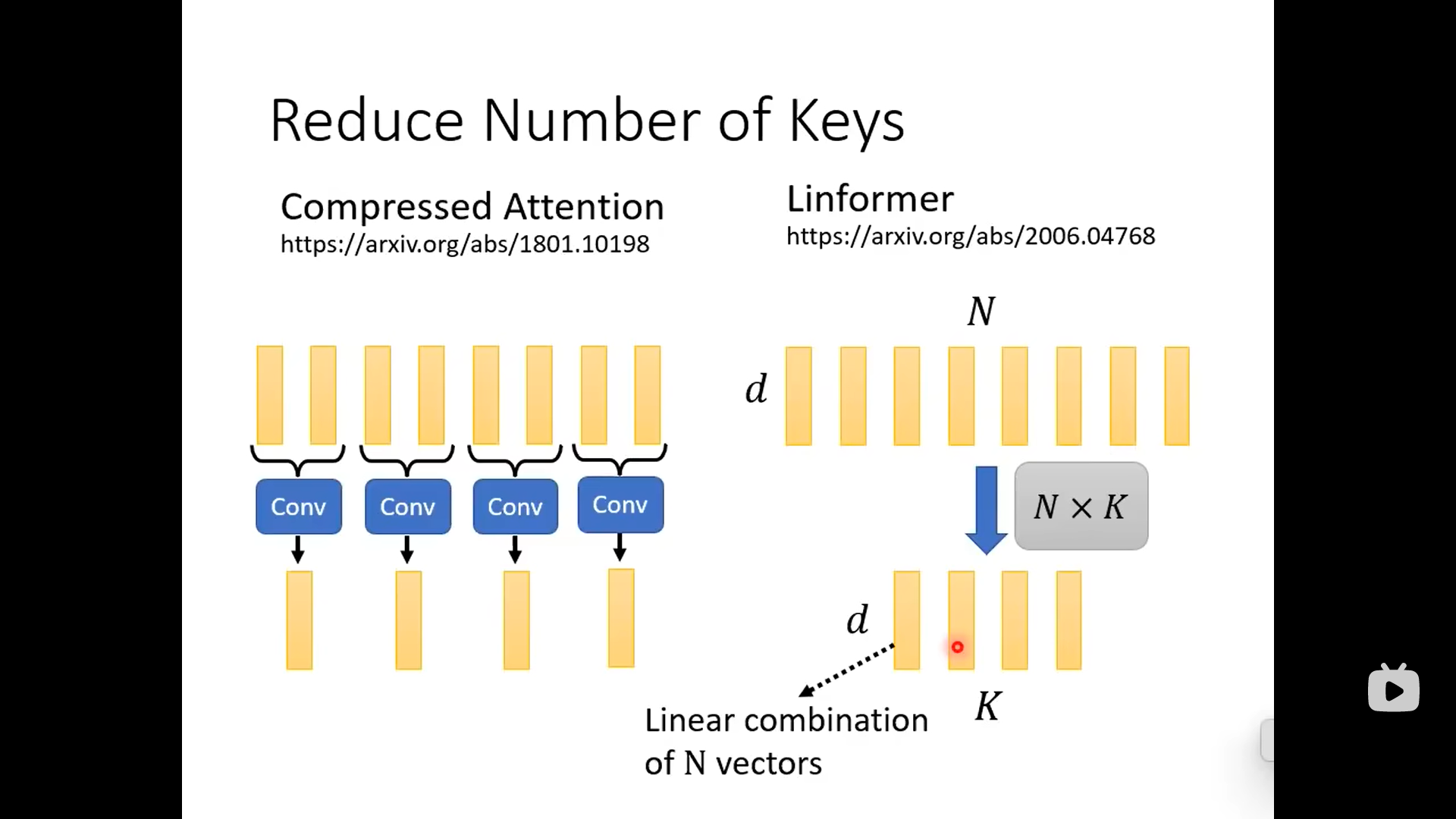
下面的做法是减少key的数目,选出代表性的key
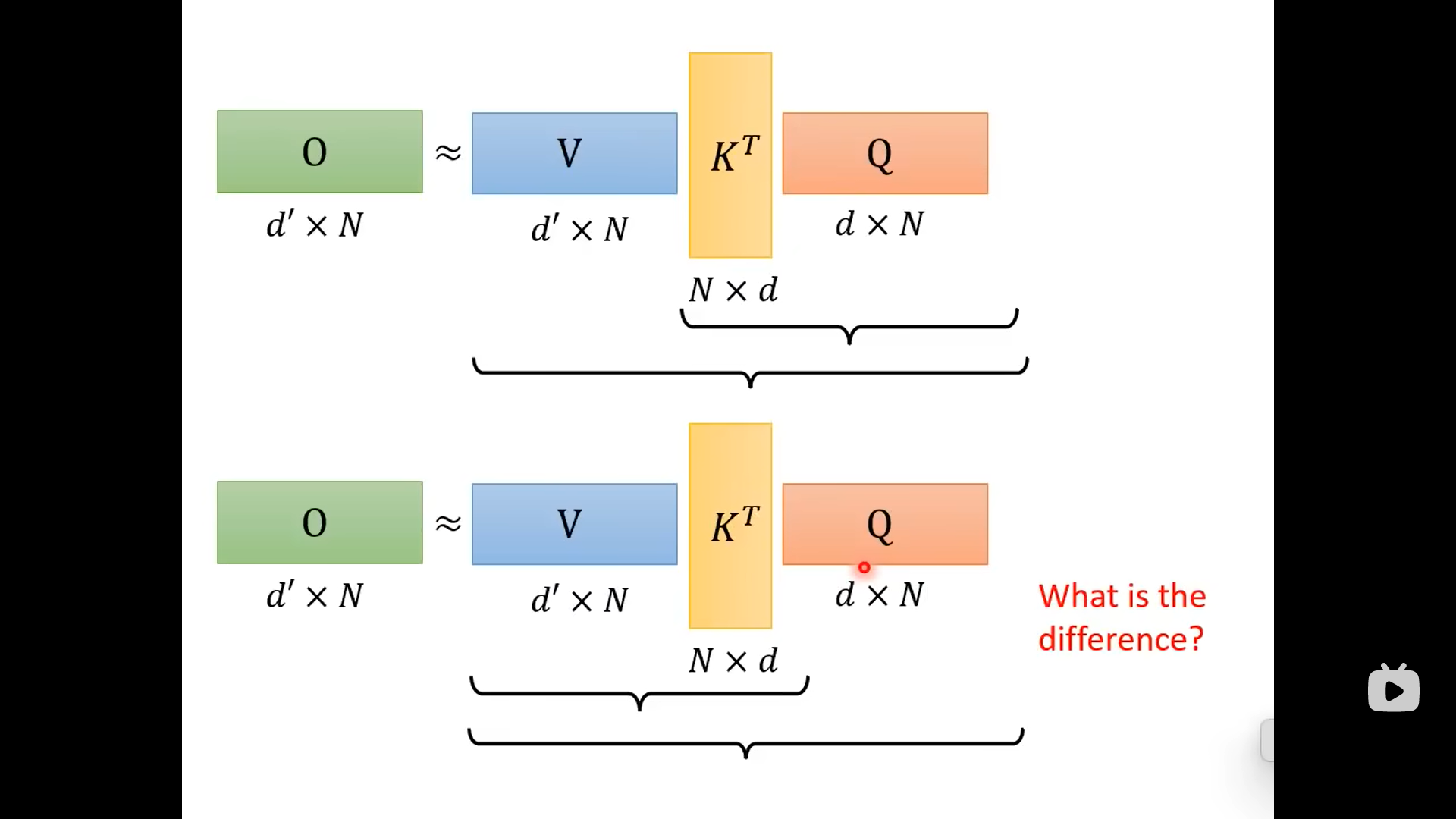
下面这个图是原始的注意力计算过程:
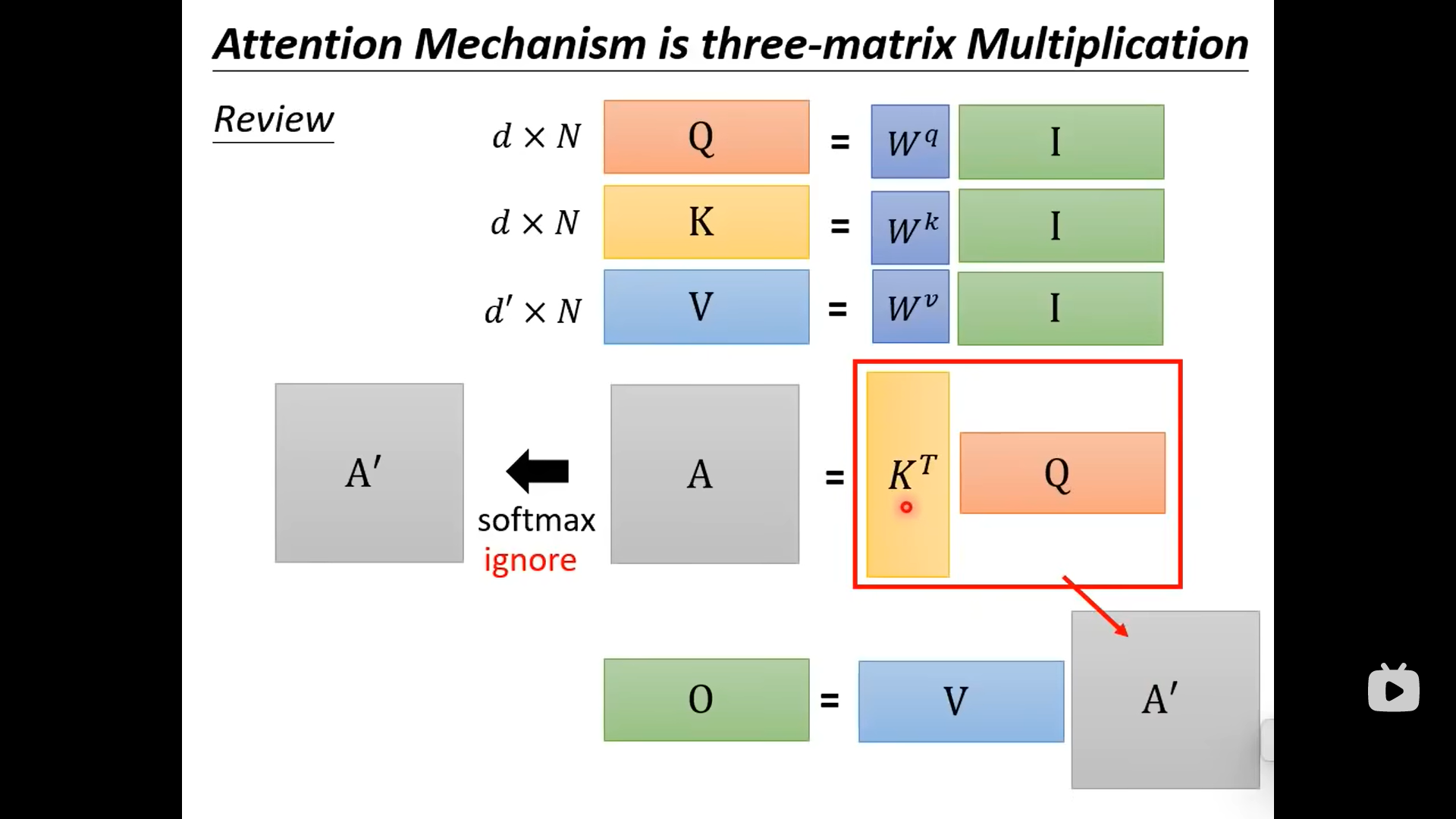
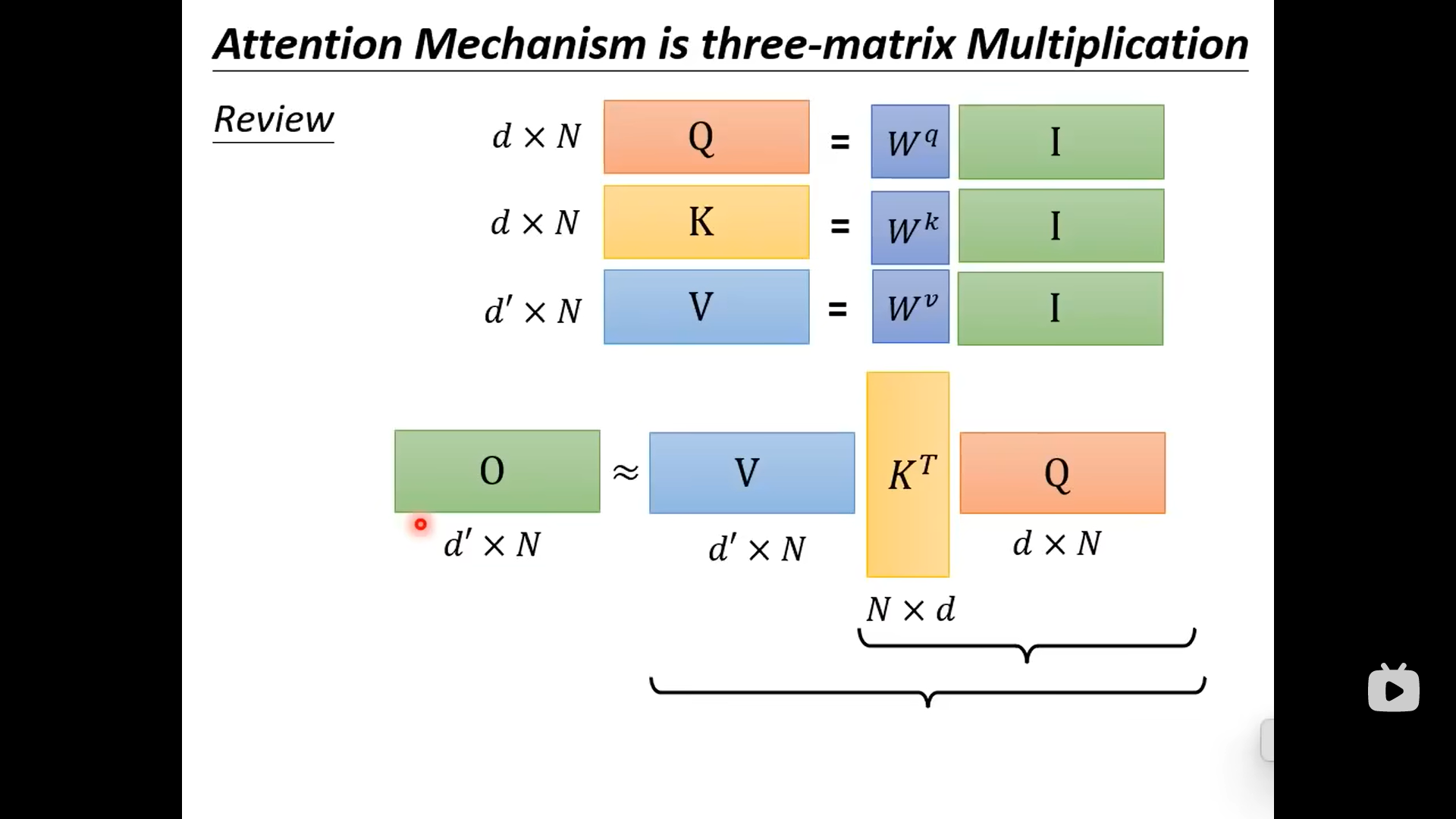
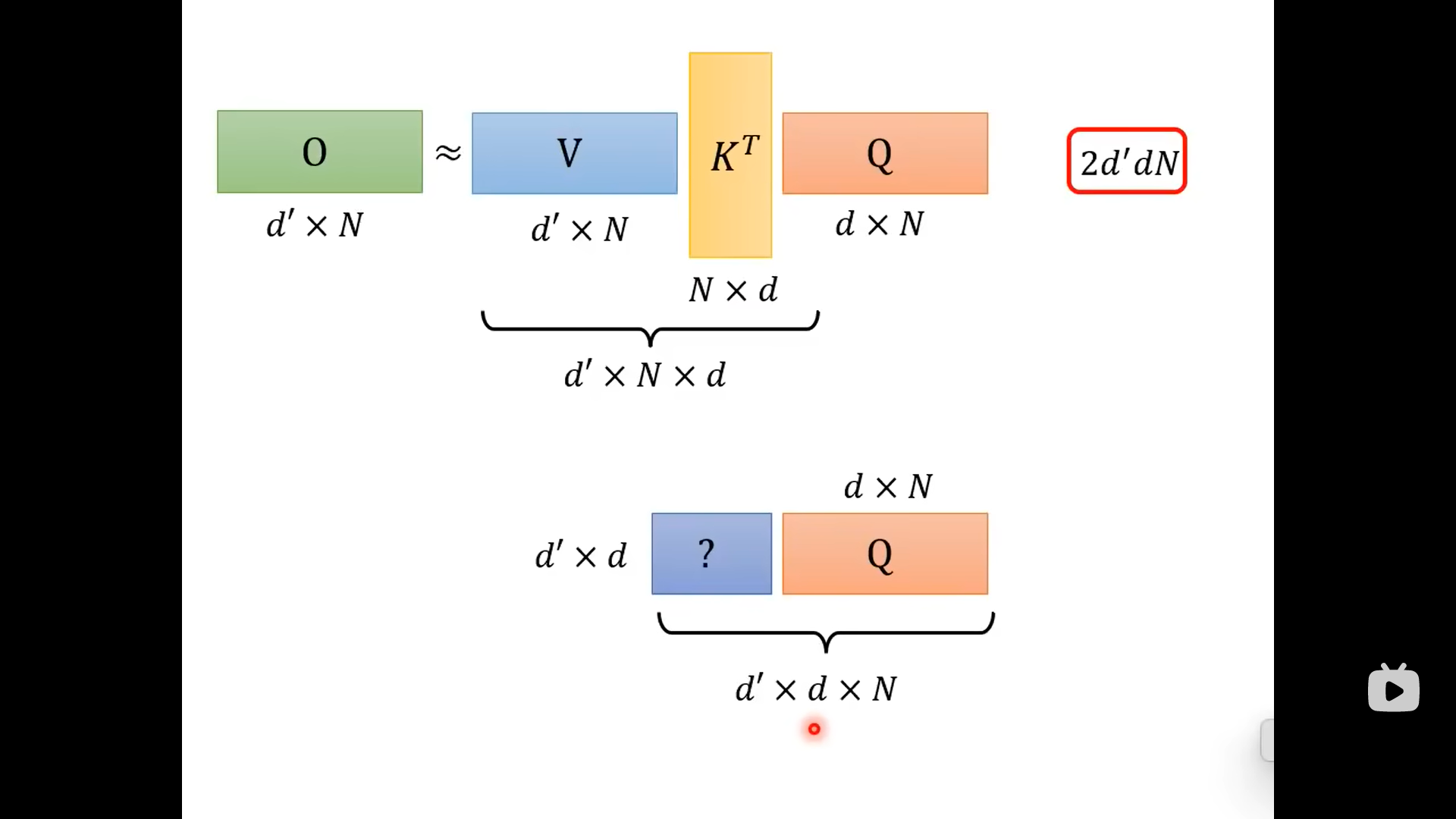
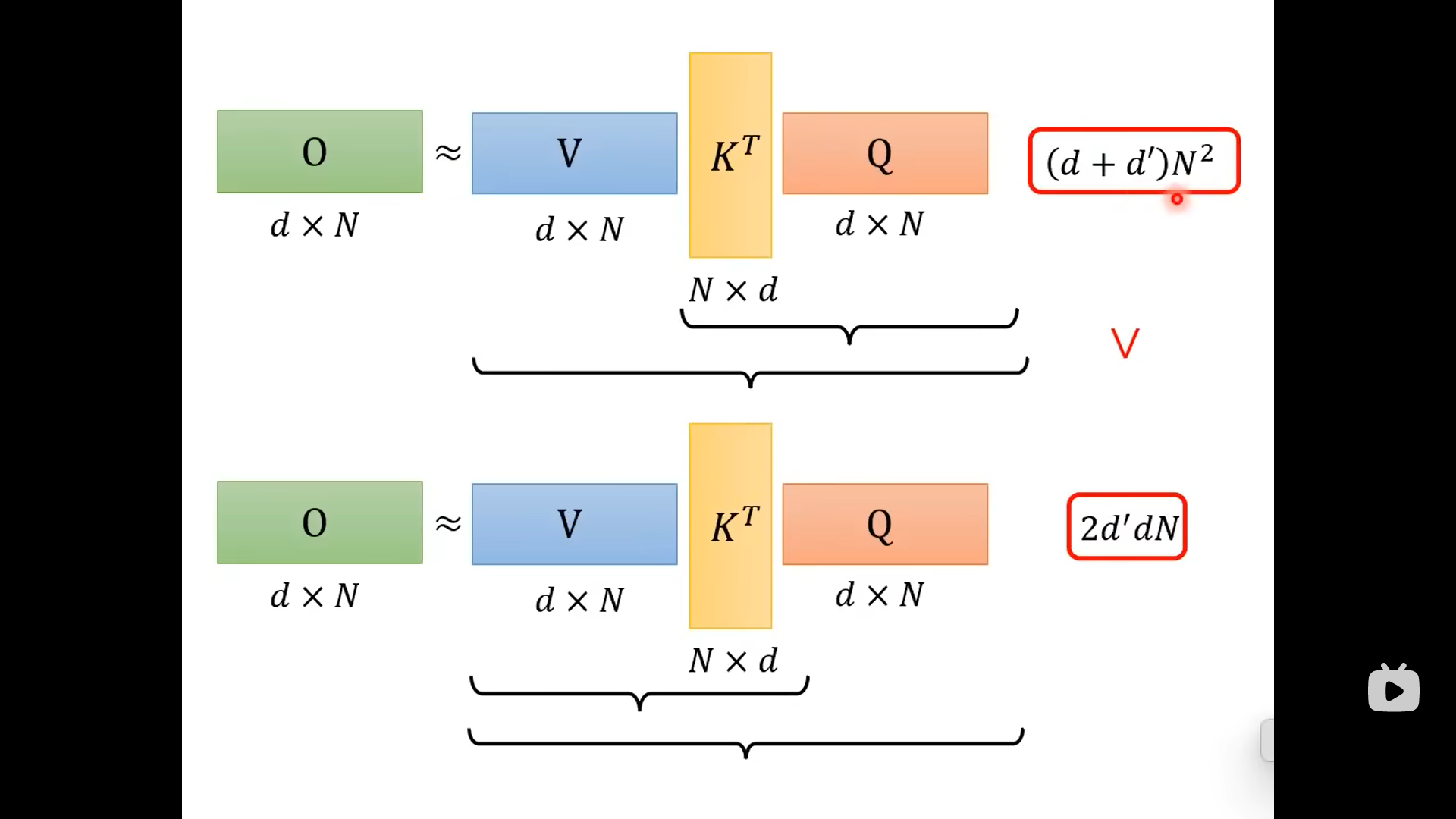
虽然两者的结果相同,但是先计算K和Q,再乘以V;与V先与K相乘,再乘以Q这两个不同的计算顺序是计算量不同的:
上面的操作是把softmax省略了,下面加上softmax:

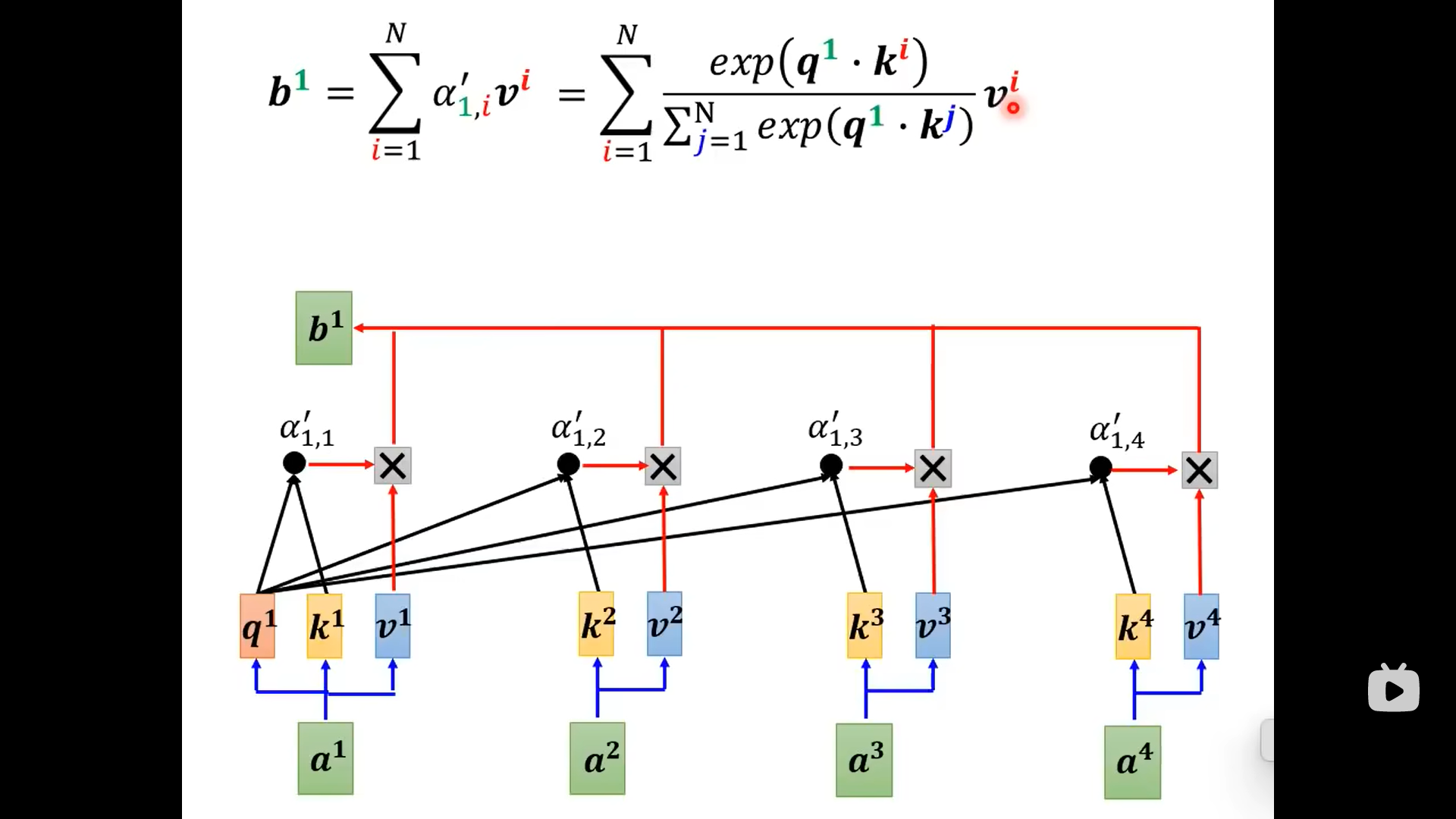
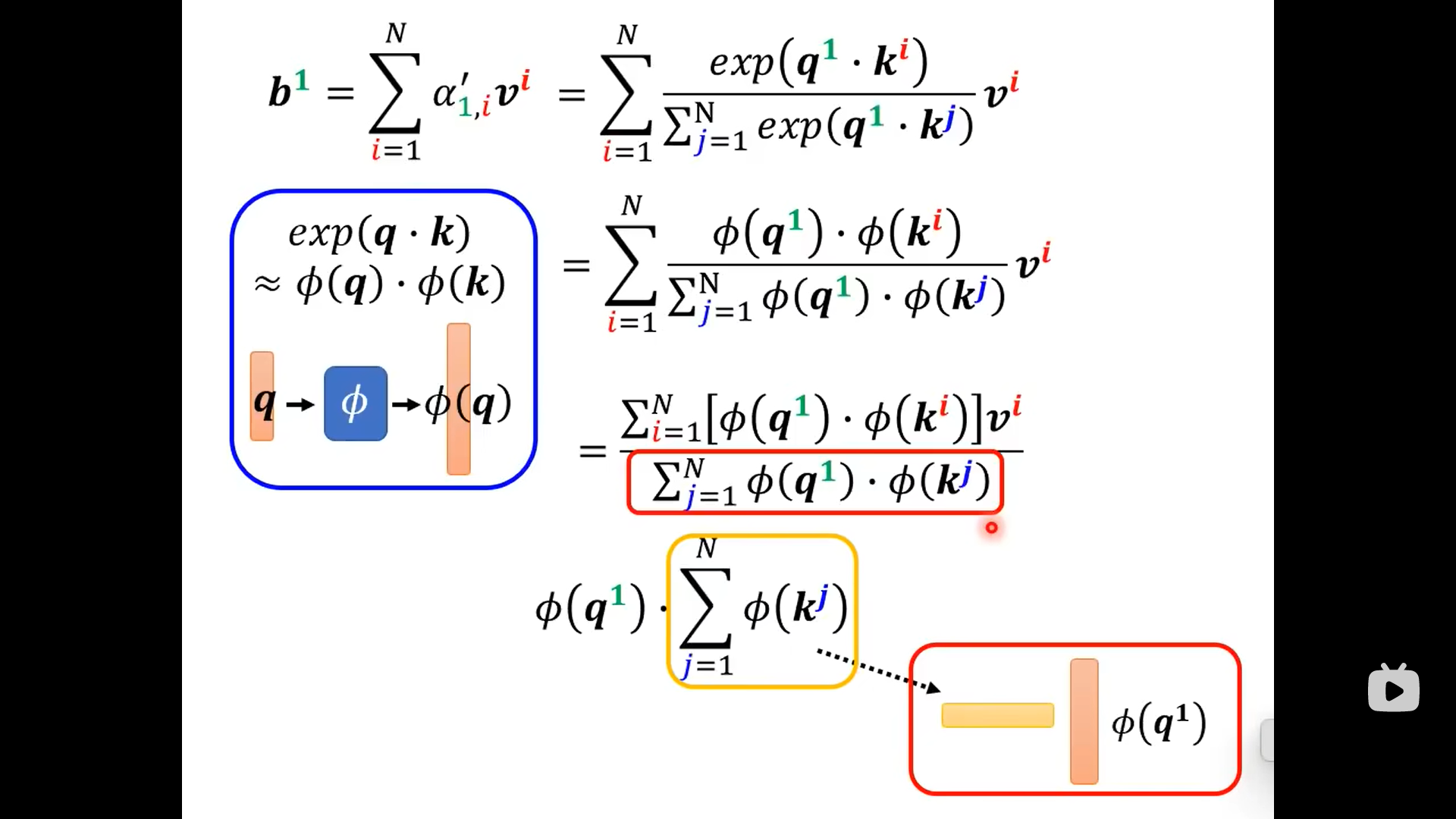

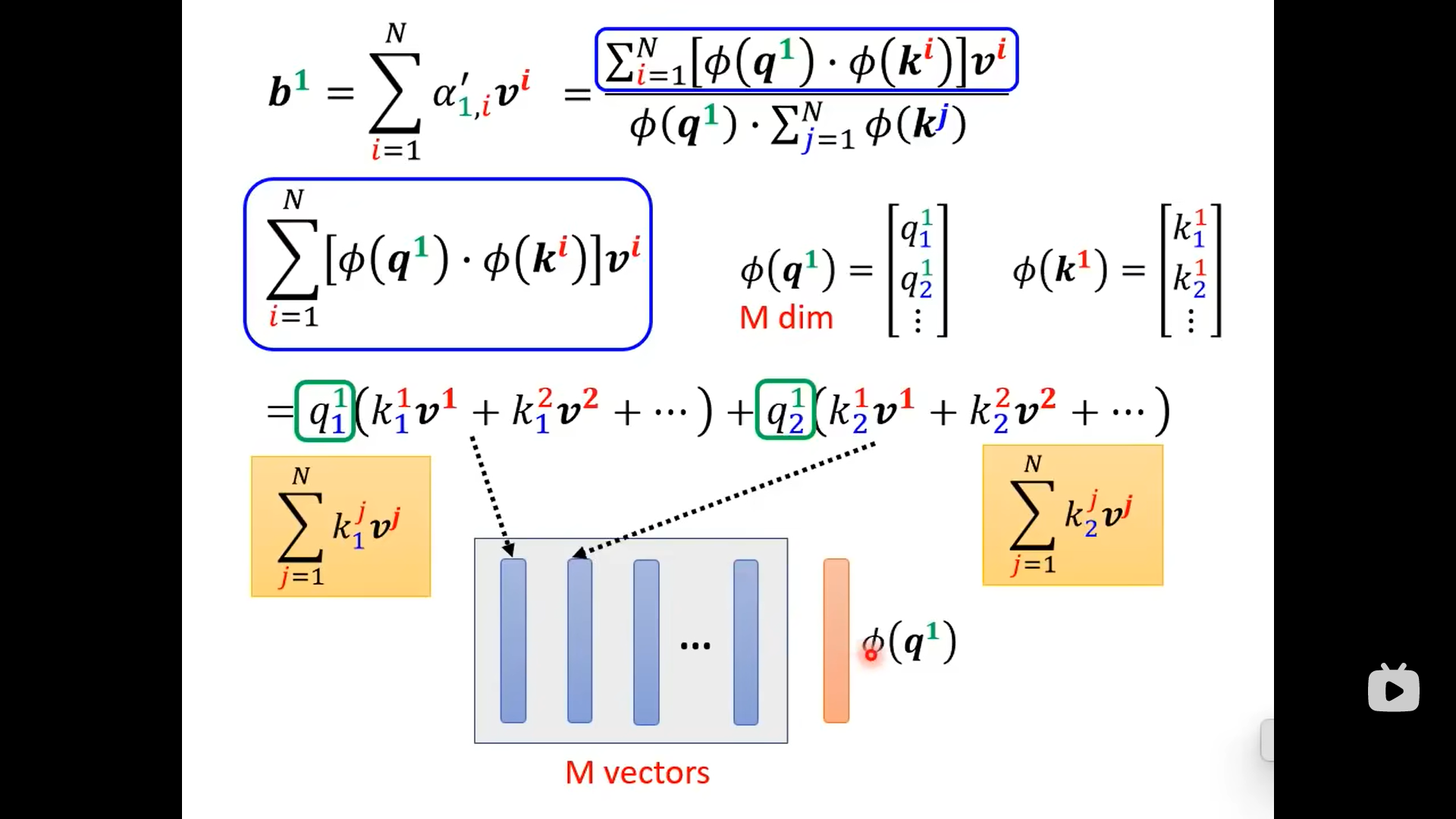
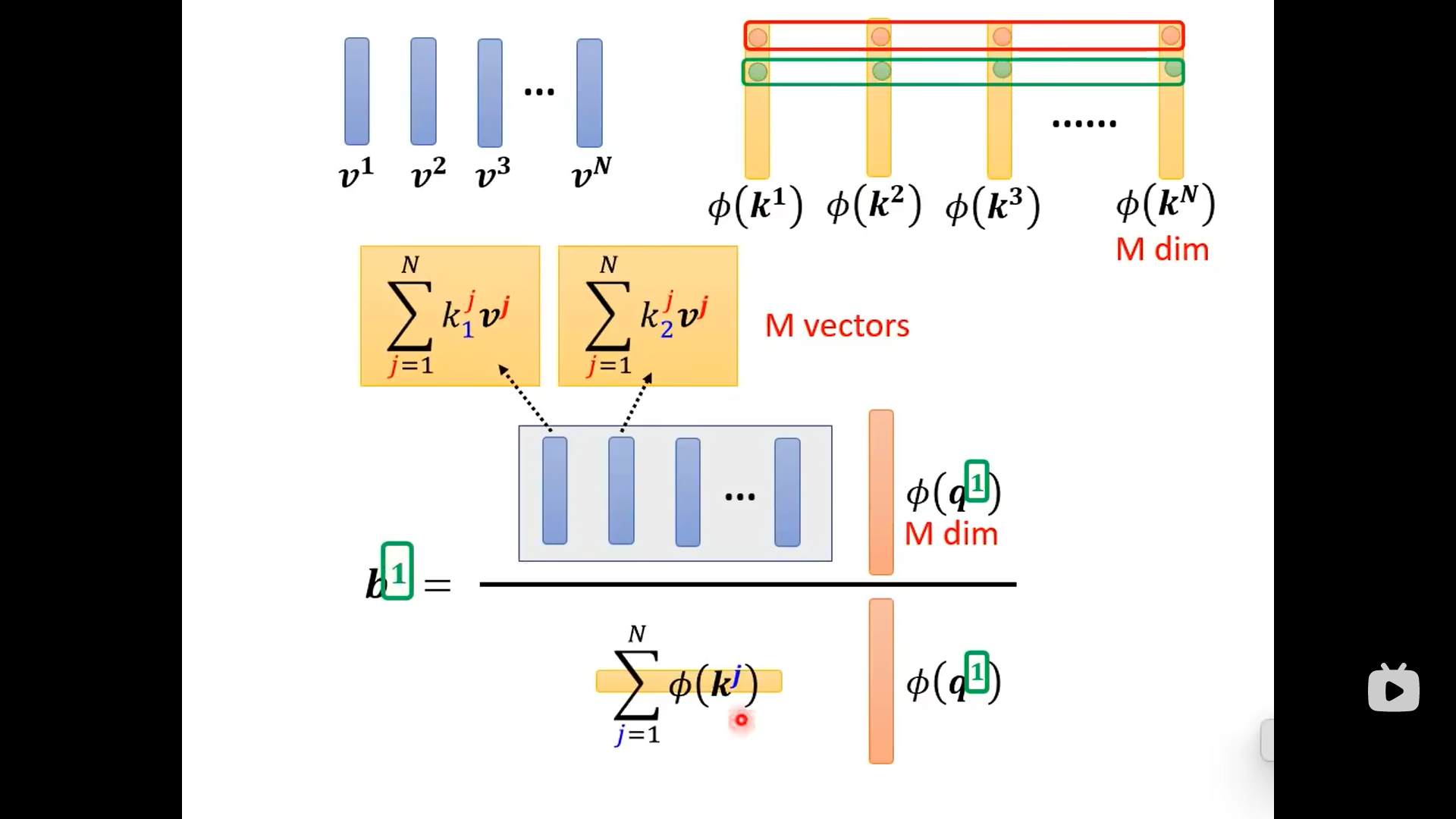
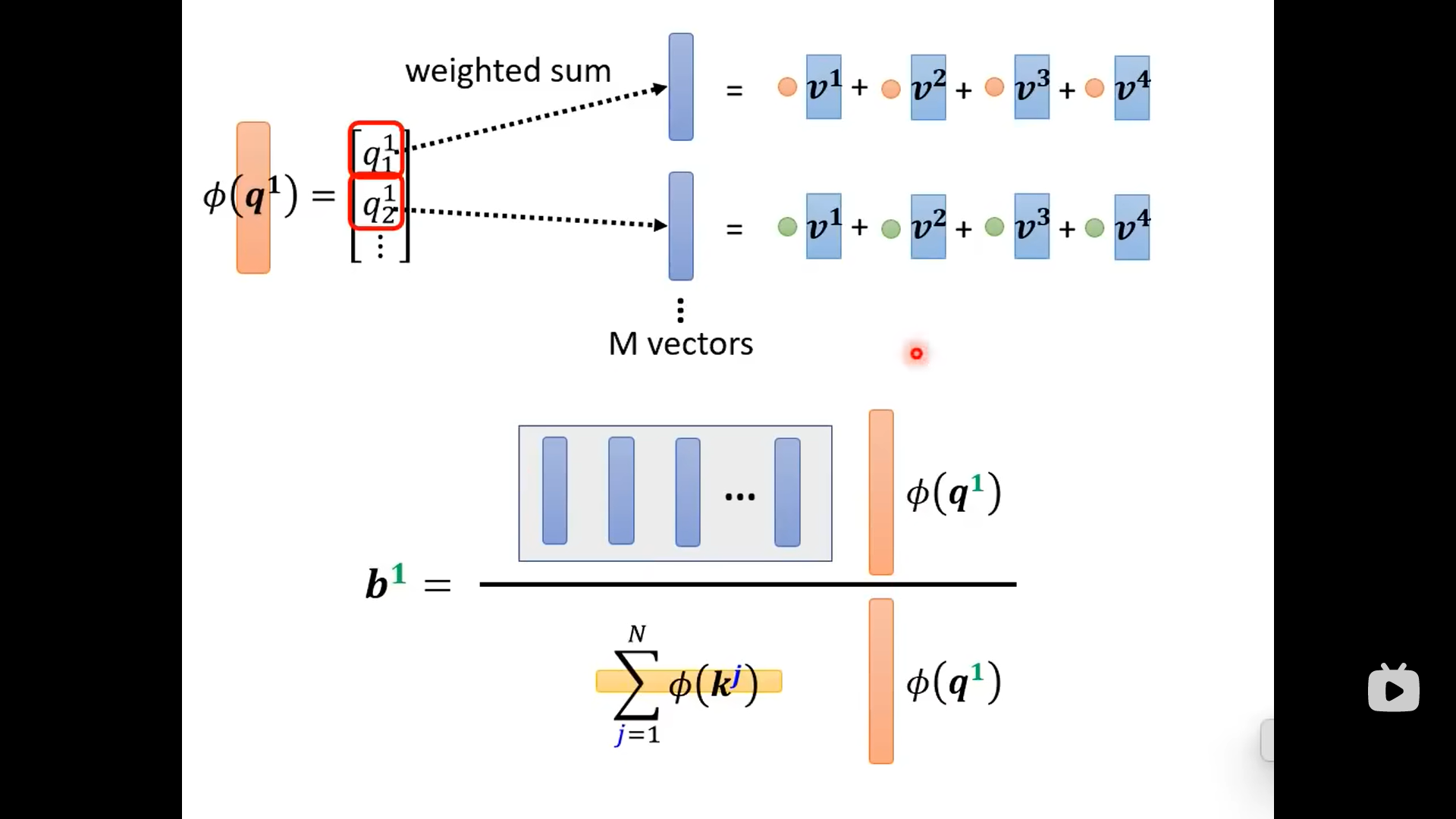
从上图可以看到,输出的的上标1只跟相关,剩下的部分不用重复计算:
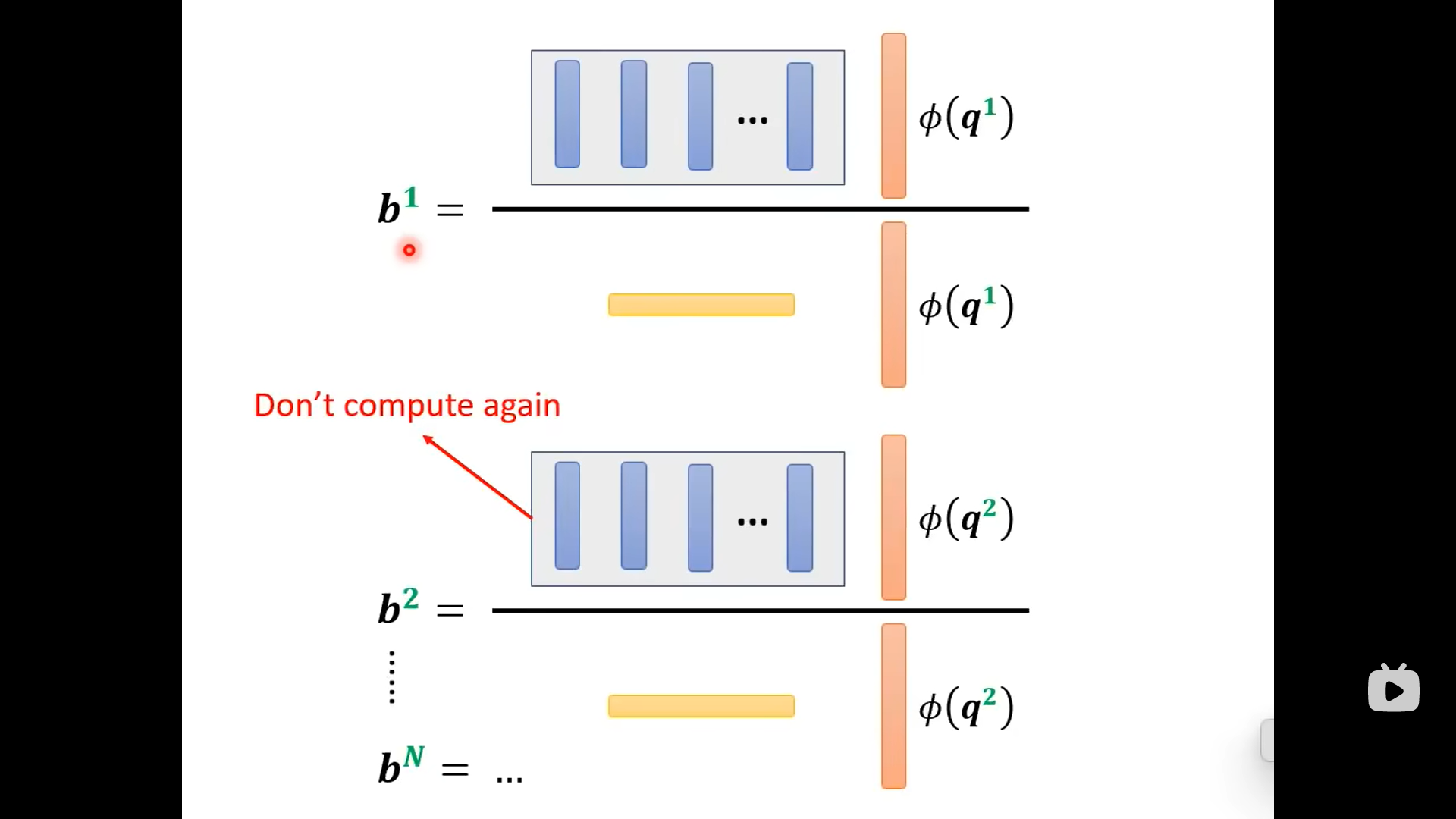

总结来看是下面的图:
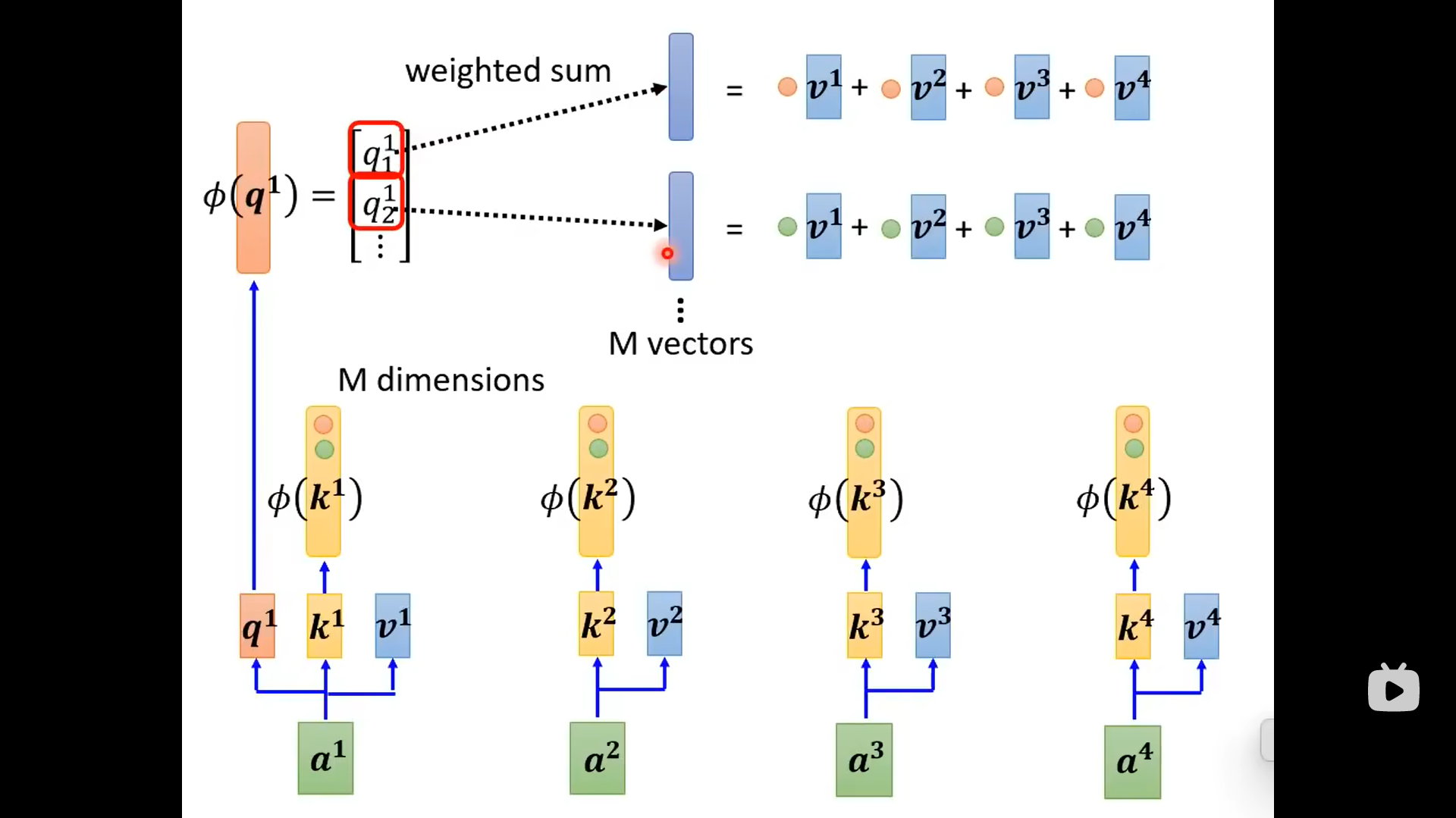
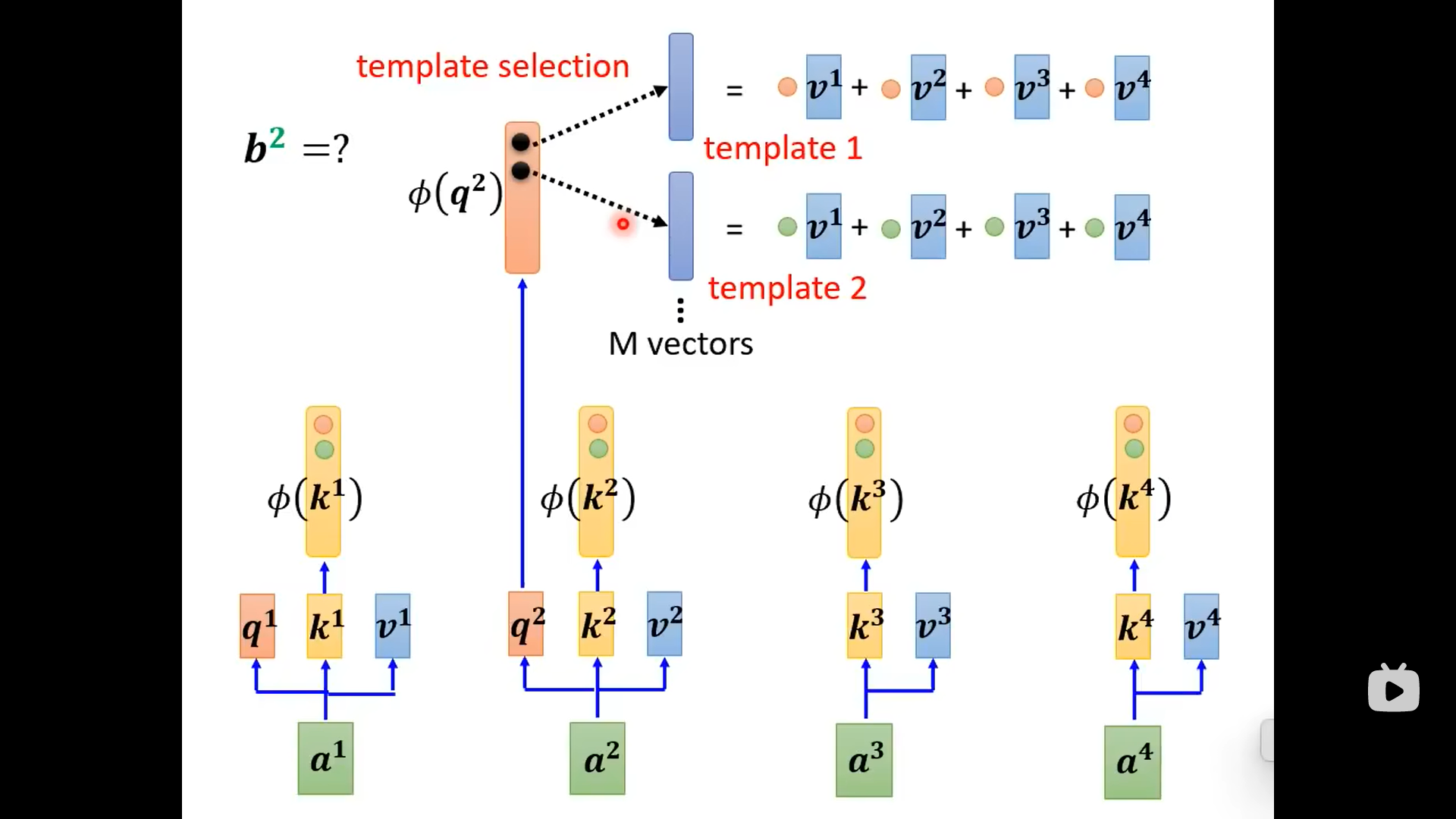
下面不同的论文有不同的拆解方式:
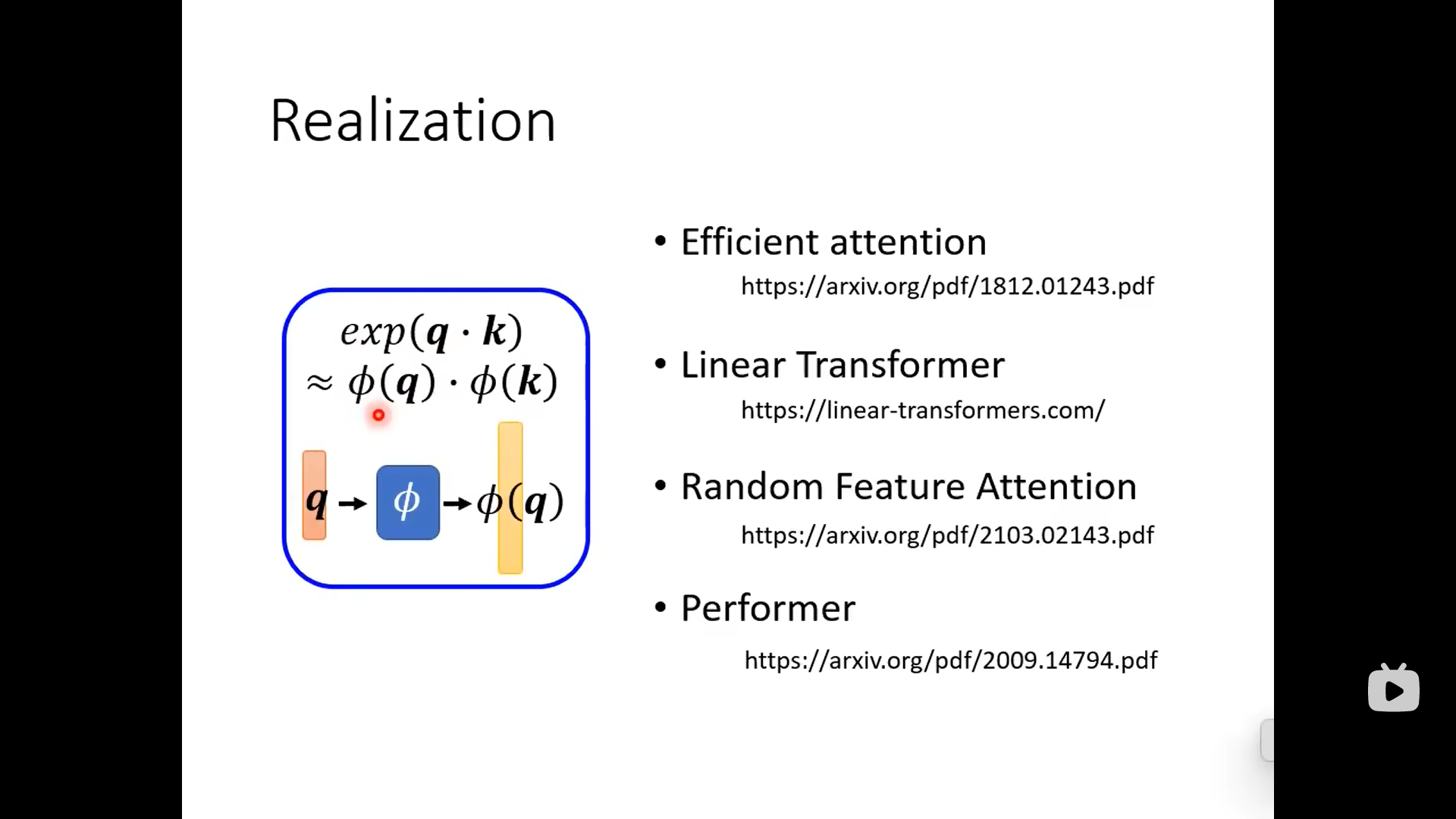
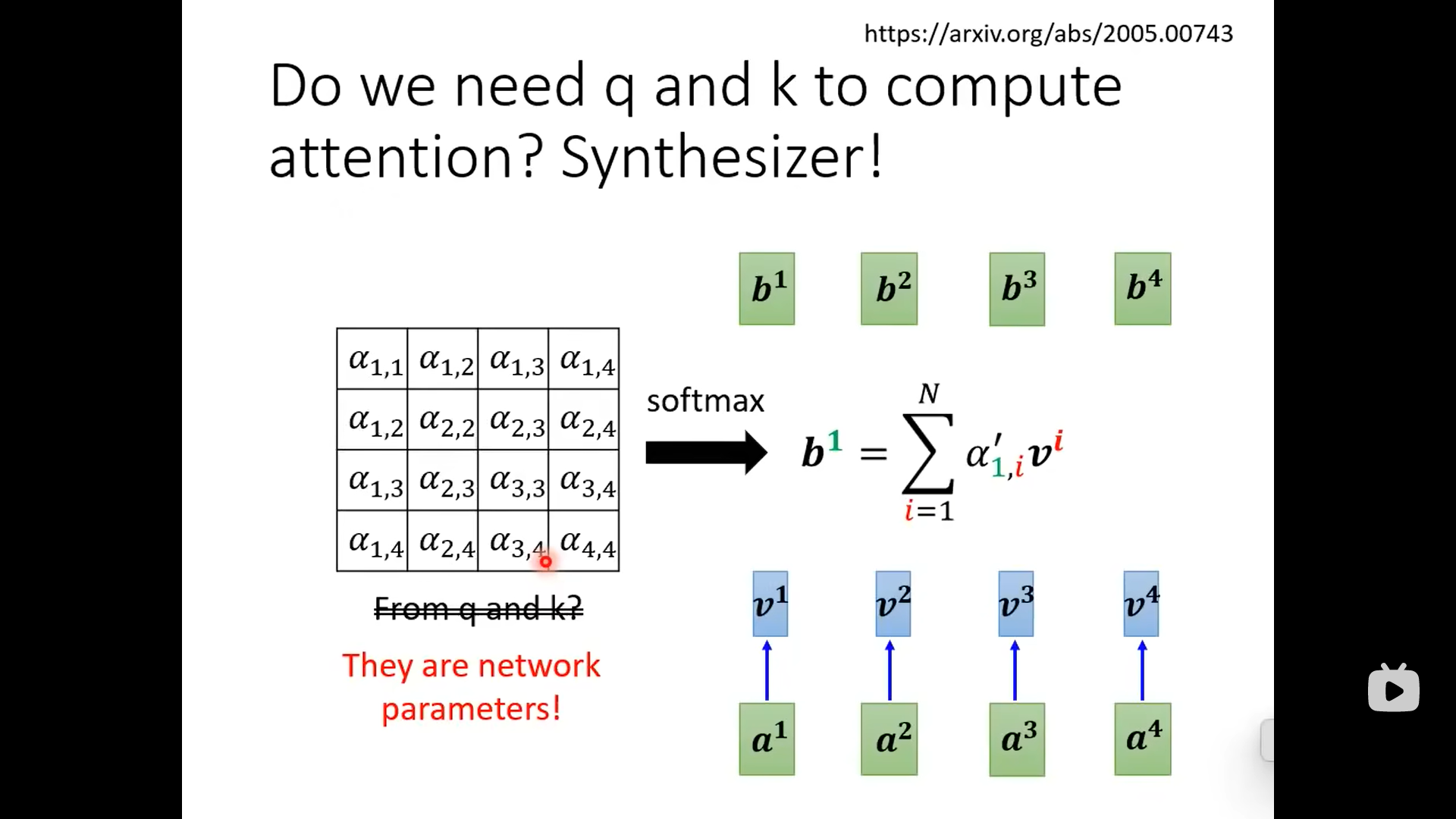
下面的attention matrix来源不是和,而是网络的参数(另一个角度):
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 XR_Wang!
公告
自 强 不 息

QQ邮箱:2233134941@qq.com




