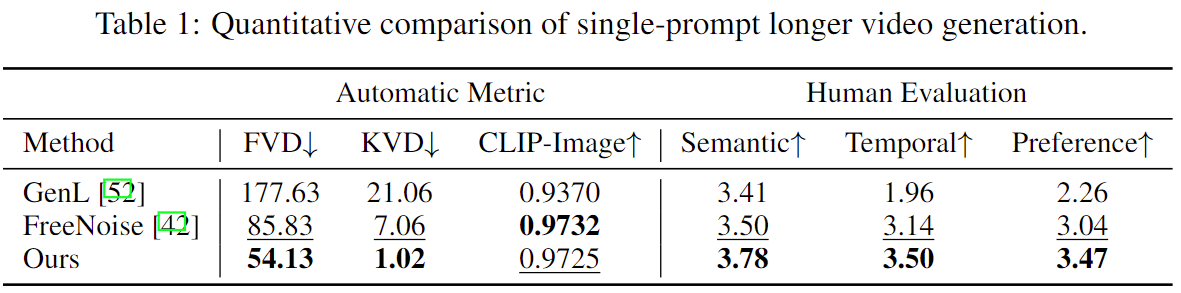
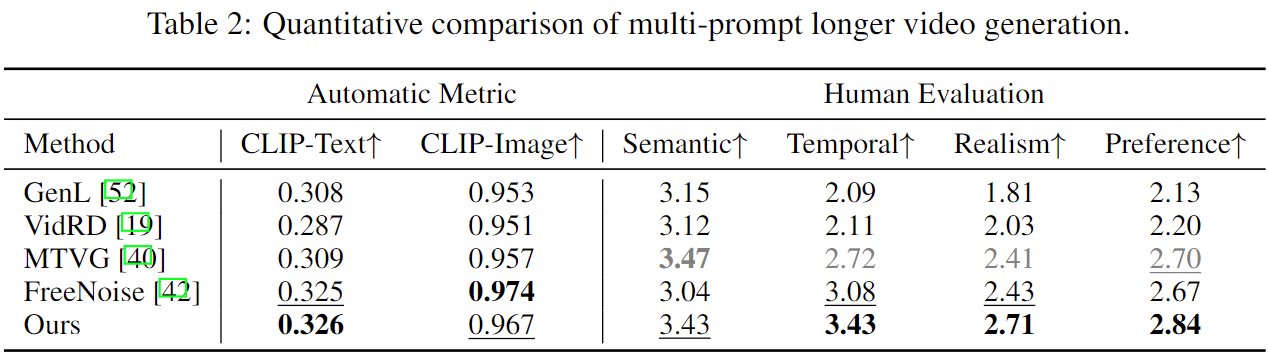
Approach
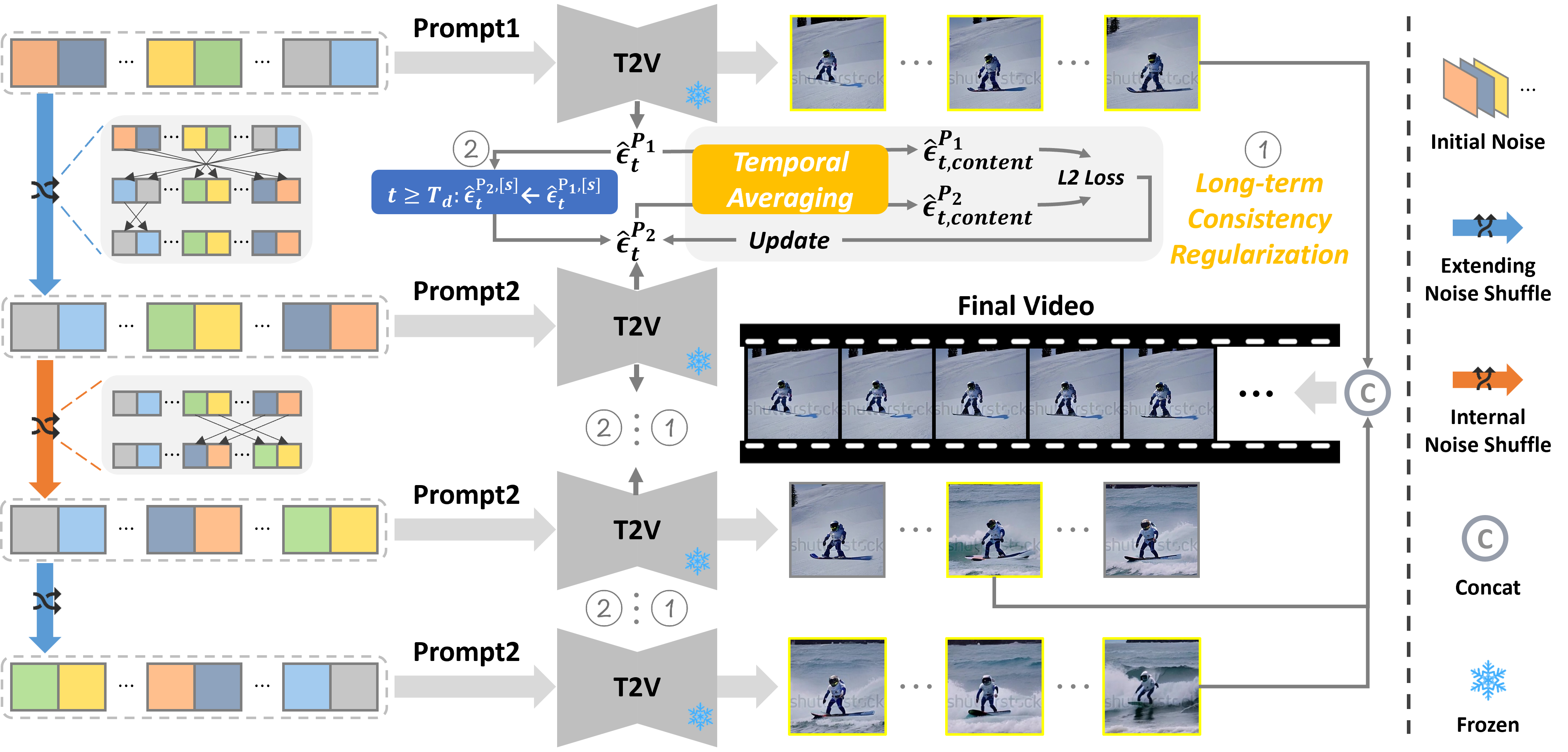
Illustration of the CoNo framework.
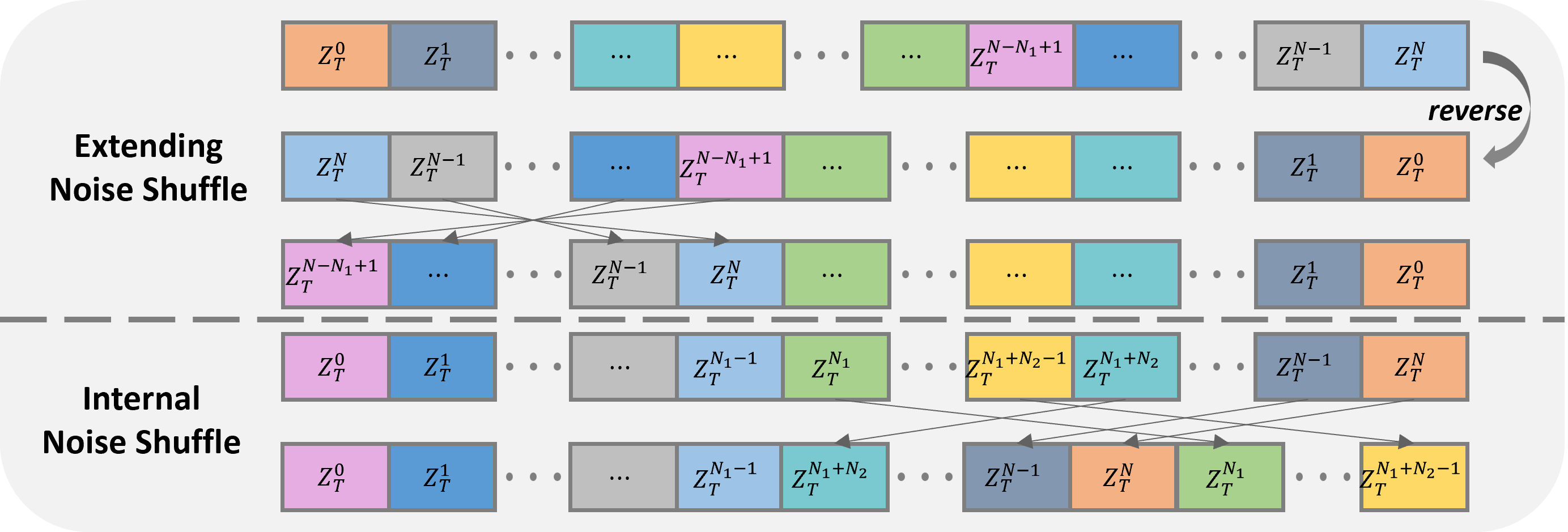
We propose a “look-back” mechanism that inserts an internal noise prediction stage between two video extending stages to enhance scene consistency. To achieve this, we design the extending and internal initial noise shuffles and constrain the denoising
trajectory using selected predicted noise (denoted as [s] in the figure). Additionally, we apply long-term consistency regularization between adjacent video clips to avoid abrupt content shifts. We obtain
the final video by concatenating the frames marked with yellow boxes from different stages.